library(tidyverse)
library(ggplot2)
library(epiR)
library(faraway)3 연관성의 검정
이 절에서는 두 변수의 연관성에 통계적 가설 검정 방법을 살펴보자.
3.1 필요한 패키지
3.2 카이제곱 검정
일단 2개의 이항변수 \(X\) 와 \(Y\) 를 고려하고 가능한 결과의 조합과 그 확률은 다음과 같은 \(2 \times 2\) 분할표로 나타낼 수 있다.
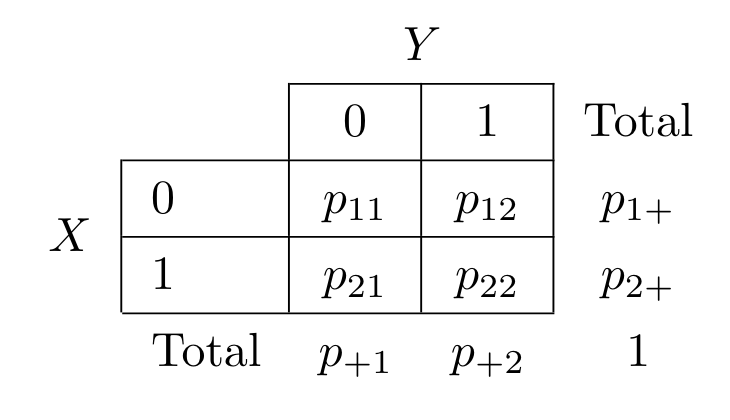
일반적으로 \(2 \times 2\) 분할표에서 다음과 같은 두 가지 가설이 가능하다.
동질성 검정(homogeneuty test)
변수 \(X\) 가 단순하게 독립 집단을 나누는 변수인 경우 (예를 들어 실험약 집단과 위약 집단) 두 그룹 간에 이항변수 \(Y\)의 성공확률이 같은지 검정하는 경우이다. 실험약 집단과 위약 집단에서 심장병이 발병할 확률이 같은지 검정을 수행할 때 귀무가설은 다음과 같다.
\[ H_0: p_{1j} = p_{2j} = p_j \]
독립성 검정(independent test)
변수 \(X\) 와 \(Y\) 가 모두 확률변수인 경우 두 변수가 독립인지 검정하는 경우이다. 예를 들어 흡연(\(X\))과 심근경색(\(Y\))의 관계를 연구하는 경우 두 사건이 모두 확률적인 사건이라고 보고 다음과 같이 독립에 대한 가설을 고려한다.
\[ H_0: p_{ij} = p_{i+} p_{+j} \]
다음과 같이 \(n\) 개의 관측값으로 구성된 \(2 \times 2\) 분할표에서 동질성과 독립성 가설을 검정하는 방법은 동일하며 따라서 굳이 두 가지 가설을 엄격하게 구별할 이유는 없다. 만약 귀무가설이 기각되면 두 변수의 연과성은 유의하다고 결론을 내린다.
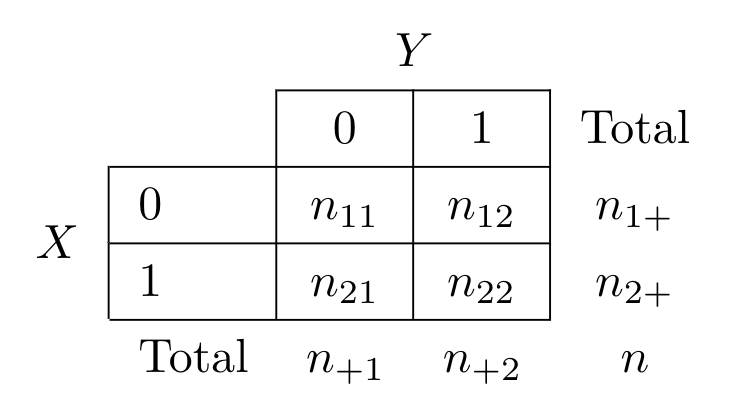
동질성과 독립성에 대한 검정은 다음과 같은 카이제곱 통계량을 사용한다.
\[ \chi^2 = \sum_{i=1}^2 \sum_{j=1}^2 \frac{(O_{ij} - E_{ij})^2}{E_ij} \tag{3.1}\]
위의 카이제곱 통계량에서 \(O_{ij} = n_{ij}\) 는 각 셀의 관측도수이며 \(E_{ij}\)는 귀무가설 하에서의 셀 도수의 예측값이다.
동질성 검정을 고려할 때 만약 귀무가설이 참이라면 확률 \(p_{1j} =p_{2j}=p_j\) 는 다음과 같이 추정할 수 있다.
\[ \hat p_{j} = \frac{n_{+j}}{n} \]
따라서 셀 \((i,j)\) 에 대한 기데 돗수 \(E_{ij}\) 는 다음과 같이 계산된다.
\[ E_{ij} =n_{i+} \hat p_j =\frac{n_{i+} n_{+j}}{n} \tag{3.2}\]
귀무가설 하에서 표본의 크기가 충분히 크면 식 3.1 의 카이제곱 검정통계량 \(\chi^2\) 는 자유도가 1인 카이제곱 분포를 따른다. 그러므로 이 사실을 이용하여 p-값을 계산하거나 기각역을 구하여 검정한다.
일반적인 \(I \times J\) 분할표도 동일한 방법으로 가설검정을 할 수 있다. 카이제곱 통계량을 구하는 방법은 \(2 \times 2\) 분할표와 유사하다. 다만 귀무가설이 참인 경우 검정통계량은 자유도가 \((I-1)(J-1)\) 인 카이제곱 분포를 따른다.
\[ \chi^2 = \sum_{i=1}^I \sum_{j=1}^J \frac{(O_{ij} - E_{ij})^2}{E_ij} \]
이제 실제 분할표에서 카이제곱 검정을 수행해 보자. 아스피린 임상실험 결과가 주어진 표 2.4 에서 아스피린의 횩과사 없는 경우, 즉 귀무가설이 참인 경우 다음과 같이 심근경색의 유무에 대한 예측 확률을 구할 수 있다.
\[ \hat p_1 = \frac{n_{+1}}{n} = \frac{139+239}{22071} = 0.0171 \] \[\hat p_2 = \frac{n_{+2}}{n} = \frac{10898+10795}{22071} = 0.9829 \]
이제 각 셀의 기대도수를 식 3.2 에 의하여 계산할 수 있다. 예를 들어 \(E_{11}\) 은 다음과 같이 계산된다.
\[ E_{11} = \frac{n_{1+}n_{+1}}{n} = n_{1+} \hat p_1 = (11037)(0.0171) = 189.03 \]
각 셀에 대한 기대도수 \(E_{ij}\) 를 구하고 식 3.1 의 카이제곱 통계량을 구하면 다음과 같다.
\[\begin{align*} \chi^2 & = \frac{(139-189.03)^2}{189.03} + \frac{(10898-10848.00)^2}{10848.00} \\ & \quad + \frac{(239-188.97)^2}{188.97} + \frac{(10795-10845.03)^2}{10845.03} \\ & = 26.94 \end{align*}\]
자유도가 1인 카이제곱 분포의 상위 5% 백분위수 \(3.84\) 이다. 위에서 구한 카이제곱 통계량의 값이 \(26.94\) 로서 \(3.84\) 보다 크므로 귀무가설을 기각한다. 즉 아스프린과 위약을 복용한 두 그룹 사이에는 심근경색이 일어날 비율에 유의한 차이가 있다.
R 에서도 카이제곱 검정을 쉽게 수행할 수 있다. 앞에서 표 2.4 의 자료를 행렬의 형태로 저장하였는데 함수 chisq.test() 를 사용하면 결과를 쉽게 구할 수 있다.
ex1dat <- matrix( c(139, 10898, 239, 10795), 2, 2, byrow=TRUE)
ex1dat [,1] [,2]
[1,] 139 10898
[2,] 239 10795chisq.test(ex1dat)
Pearson's Chi-squared test with Yates' continuity correction
data: ex1dat
X-squared = 26.408, df = 1, p-value = 2.764e-07분할표에서의 기대도수 \(E_{ij}\) 는 다음과 같이 얻을 수 있다.
chisq.test(ex1dat)$expected [,1] [,2]
[1,] 189.0257 10847.97
[2,] 188.9743 10845.033.3 코크란-맨텔-헨젤 검정
임상실험이나 의학연구는 여러 나라 또는 여러 병원들에서 진행되는 경우가 있다. 이러한 경우 국가나 병원의 고유한 특성에 따라서 실험의 결과가 다르게 나타날 수 있다. 이렇게 그룹에 의한 효과를 그룹 효과 또는 층(strata)에 의한 효과라고 한다. 예를 들어 진통제에 대한 효과는 그 나라의 문화나 관습에 따라서 효과의 차이가 나타날 수 있다. 또한 여러 개의 변원에서 연그ㅜ가 동시에 진행된다면 병원의 규모, 위치, 환자들의 특성에 따라서 치료 효과의 차이가 나타날 수 있다.
이렇게 그룹에 따른 차이가 예상되는 경우 그룹의 효과를 제어하면서 처리 효과의 차이를 검정하는 방법이 필요하다. 이렇게 여러 개의 층으로 구성된 독립집단에서 얻은 자료에서 층에 의한 횩과를 통제하면서 동질성 또는 독립성 검정을 수행하는 방법을 코크란-맨텔-헨젤 검정 (Cochran-Mantel-Haenzel test)라고 한다.
아래와 같이 \(K\) 개의 독립집단(또는 층)에서 각각 얻은 \(K\) 개의 \(2 \times2\) 분할표가 있다고 하자.
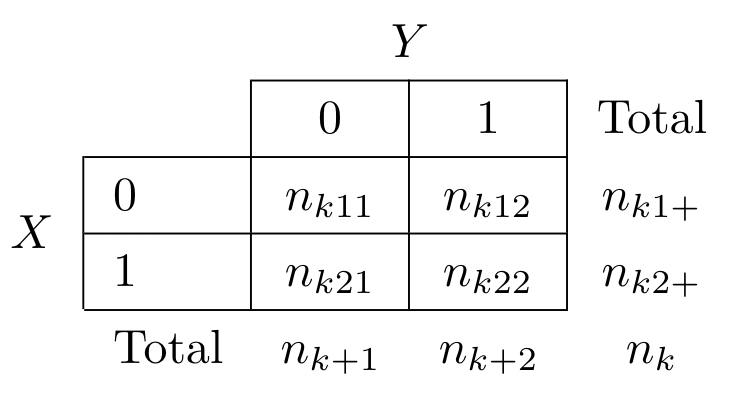
\(K\) 개의 독립집단이 있고 성공의 확률이 \(p_1\), 실패의 학률이 \(p_2\) 라고 한다면 처리의 효과를 전체적으로 비교하는 가설은 다음과 같다.
\[ H_0: p_1 =p_2 \quad \text{sv.} \quad H_1: p_1 \ne p_2 \]
이제 귀무가설의 가정 하에서 각 분할표에서 \(n_{k11}\) 에 대한 기대도수 \(\mu_{k11}\) 와 그 분산 \(v_{k11}\) 을 다음과 같이 계산한다.
\[ \mu_{k11} = E(n_{k11} | H_0) = \frac{ n_{k1+} n_{k+1} }{ n_k} \]
\[ v_{k11} = V ( n_{k11} | H_0) = \frac{ n_{k1+} n_{k2+} n_{k+1} n_{k+2} }{n^2_k (n_k-1)} \]
이제 가설검정을 위한 통계량 \(Q_{CMH}\) 은 다음과 같다.
\[ Q_{CMH} = \frac{ \left [ \sum_{k=1}^K (n_{k11} - \mu_{k11}) \right ]^2 }{\sum_{k=1}^K v_{k11}} \tag{3.3}\]
귀무가설이 참인 경우 검정통계량 \(Q_{CMH}\) 은 자유도가 \(1\) 인 카이제곱 분포를 따른다.
이제 Agresti (2012) 의 6.3절에 있는 다기관 임상시험(multi-center clinical trial) 의 예제를 살펴보자. 아래 표는 모두 8개의 독립적인 병원에서 감염 치료제에 대한 효과에 대한 실험을 실시하여 얻은 자료이다.
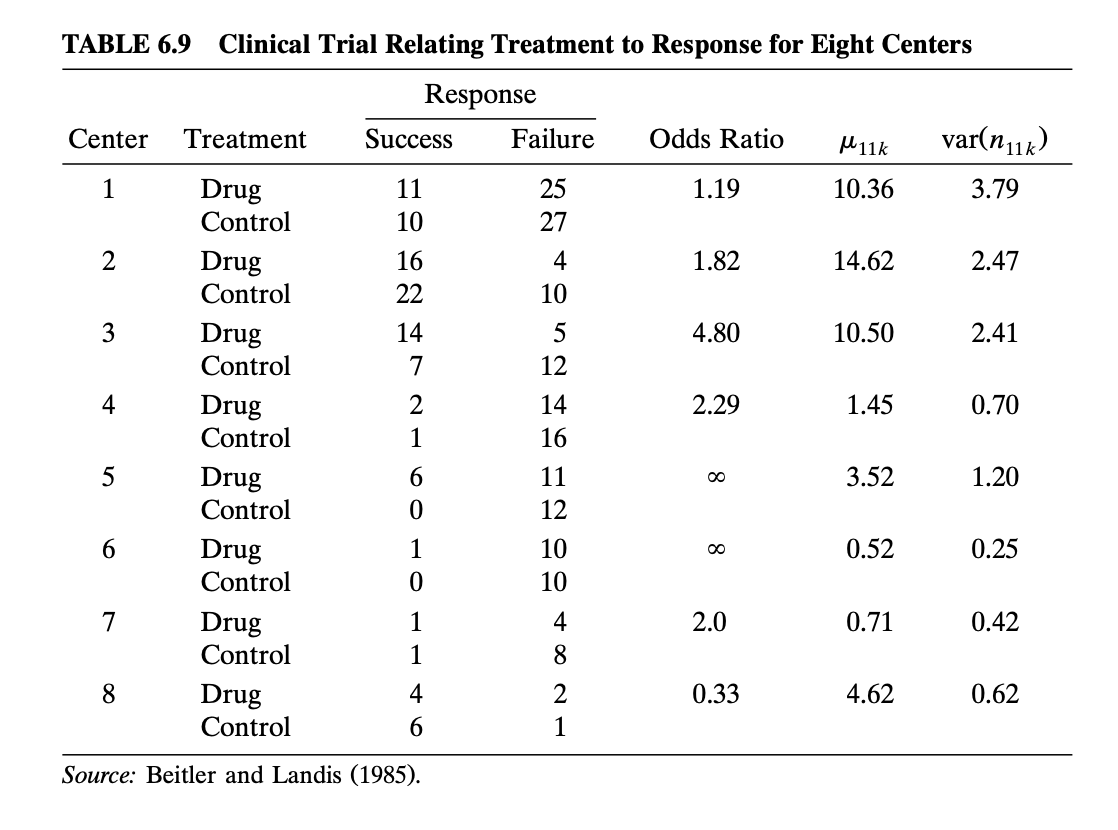
마지막 병원을 제외한 7개의 병원에서 치료제의 효과가 긍정적으로 나타났다. 여기서 주목할 점은 병원에 따라서 연관성의 강도가 매우 다르게 나타날 수 있다는 것이다.
이제 각 병원을 층(strata)로 고려하고 병원의 효과를 제어하면서 식 3.3 의 검정 통계량 \(Q_{CMH}\) 를 이용하여 치료제의 효과가 있는지 검정해보자. 검정은 아래와 같이 R 프로그램을 이용한다. 함수 mantelhaen.test() 는 코크란-맨텔-헨젤 검정을 수행하는 함수이다.
beitler <- c(11,10,25,27,16,22,4,10,14,7,5,12,2,1,14,16,6,0,11,12,1,0,10,10,1,1,4,8,4,6,2,1)
beitler <- array(beitler, dim=c(2,2,8))
beitler, , 1
[,1] [,2]
[1,] 11 25
[2,] 10 27
, , 2
[,1] [,2]
[1,] 16 4
[2,] 22 10
, , 3
[,1] [,2]
[1,] 14 5
[2,] 7 12
, , 4
[,1] [,2]
[1,] 2 14
[2,] 1 16
, , 5
[,1] [,2]
[1,] 6 11
[2,] 0 12
, , 6
[,1] [,2]
[1,] 1 10
[2,] 0 10
, , 7
[,1] [,2]
[1,] 1 4
[2,] 1 8
, , 8
[,1] [,2]
[1,] 4 2
[2,] 6 1mantelhaen.test(beitler, correct=FALSE)
Mantel-Haenszel chi-squared test without continuity correction
data: beitler
Mantel-Haenszel X-squared = 6.3841, df = 1, p-value = 0.01151
alternative hypothesis: true common odds ratio is not equal to 1
95 percent confidence interval:
1.177590 3.869174
sample estimates:
common odds ratio
2.134549 검정 통계량 \(Q_{CMH}\)의 값이 \(6.3841\) 이고 p-값은 \(0.0115\) 이므로 귀무가설을 기각한다.
3.4 맥나마 검정
연속형 변수에서 짝지은 자료를 비교할 때 사용하는 방법이 대응 t-검정(paired t-test) 또는 짝표본 t-검정이다. 예를 들어 천식환자가 A약을 먹고 폐활량을 측정하고 일정 기간이 지나서 같은 환자가 B약을 먹고 폐활량을 측정하면 두 관측값은 독립이 아나다. 따라서 이러한 경우 독립 t-검정이 아닌 대응 t-검정을 시용한다.
이제 이산형 변수가 짝으로 나타나는 경우를 생각해보자. 예를 들어 눈병 치료에 사용되는 A약과 B약의 효과를비교하기 위하여 각각의 약을 환자의 오른쪽 눈과 왼쪽 눈에 처치를 하고 치료의 여부를 관측하였다고 하자.
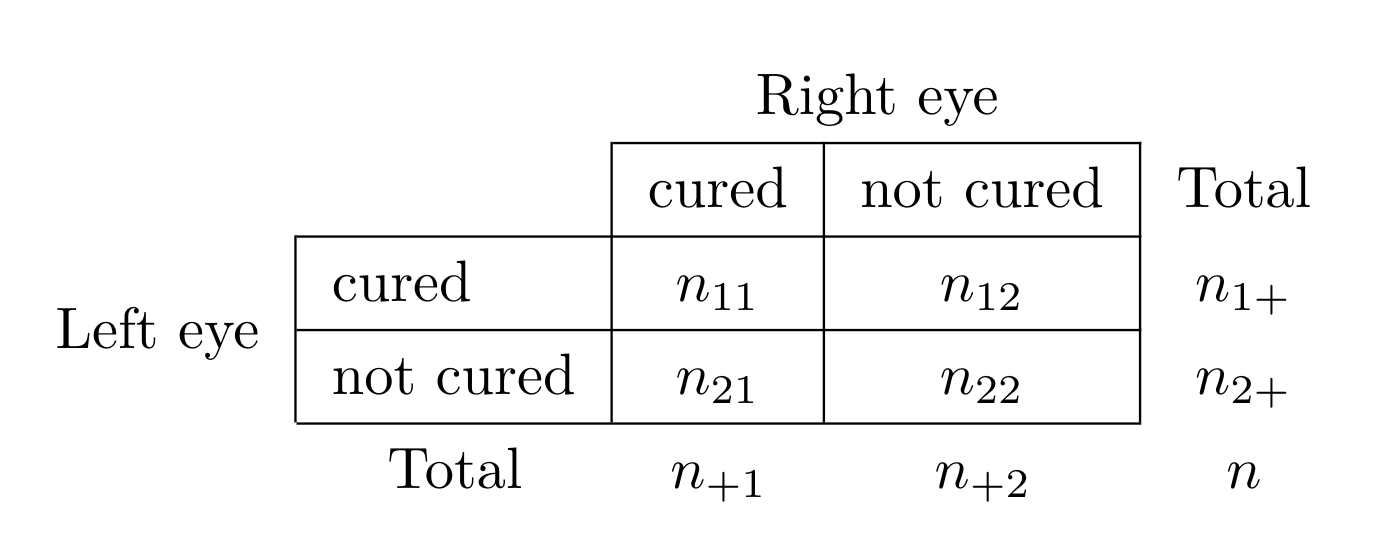
위의 표에서 \(n_{11}\) 은 A약과 B약의 효과가 모두 나타난 환자의 도수이다. \(n_{12}\) 은 A약은 효과가 있고 B약은 효과가 없는 환자의 도수이다. 이러한 자료는 앞에서 배운 카이제곱 검정을 적용할 수 없다.
이제 일반적으로 짝표본에서 나온 자료가 다음 표와 같이 얻어졌다고 가정하자.
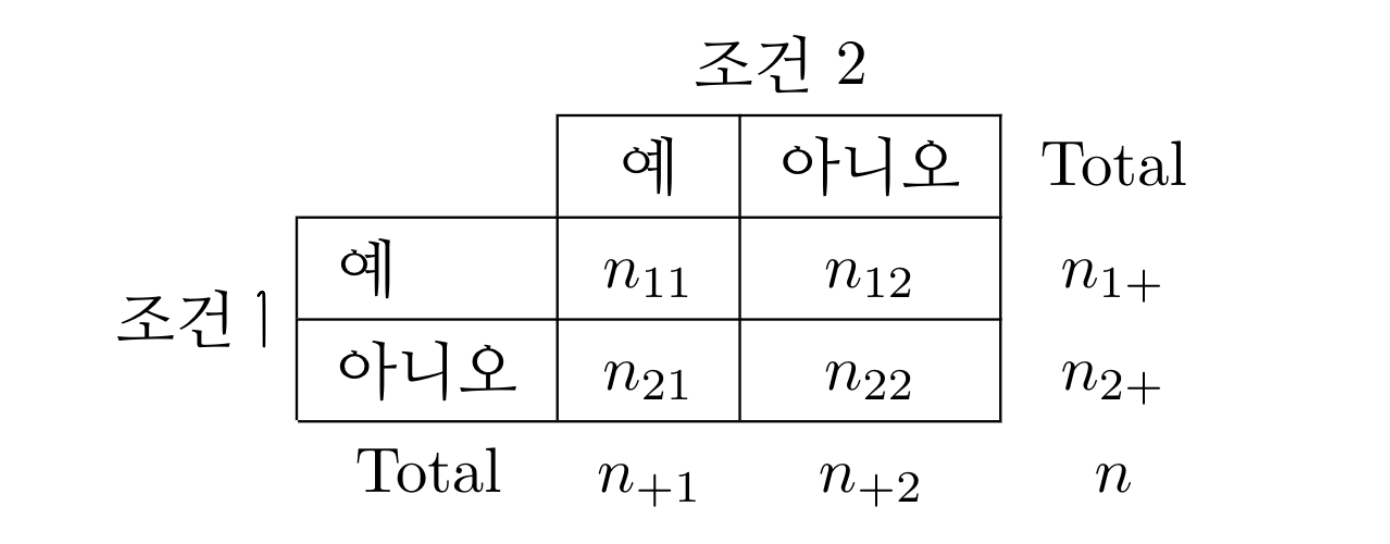
이제 조건 1 에서 성공의 확률을 \(p_1\) 이라고 하고 조건 2에서 성공의 확률을 \(p_2\) 라고 하면 짝표본에서 얻어진 분할표 그림 3.6 에서 관심있는 가설은 다음과 같다.
\[ H_0: p_1 =p_2 \quad \text{sv.} \quad H_1: p_1 \ne p_2 \]
분할표 그림 3.6 에서 \(p_1\) 과 \(p_2\)의 추정량은 다음과 같다.
\[ \hat p_1 = \frac{n_{1+}}{n}, \quad \hat p_2 = \frac{n_{+1}}{n} \]
\(p_1\) 과 \(p_2\)의 추정량의 차이는 두 조건에 따른 결과가 일치하지 않는 도수 \(n_{12}\)와 \(n_{21}\)의 차이에 의존한다.
\[ \hat p_1 -\hat p_2 = \frac{n_{1+}}{n} - \frac{n_{+1}}{n} = \frac{n_{11} + n_{12}}{n} - \frac{n_{11} + n_{21}}{n} = \frac{n_{12} - n_{21}}{n} \]
맥나마 검정(McNemar Test)는 도수 \(n_{12}\)와 \(n_{21}\)에 의거하여 두 확률이 같은지 검정하는 방법을 제시하였다. 맥나마 검정을 위한 통계량은 다음과 같다.
\[ Q_{M} = \frac{ (n_{12}-n_{21})^2}{n_{12} + n_{21}} \tag{3.4}\]
맥나마 검정 통계량 \(Q_{M}\)은 귀무가설 하에서 근사적으로 자유도가 1인 카이제곱 분포를 따른다.
다음은 1600명 영국 시민들의 수상에 대한 지지 여부를 두 개의 연속된 여론 조사에서 수집한 자료이다 (Agresti 2012 의 10장 참조). 이제 두 시점에서 수상에 대한 지지율이 같은지 아닌지 R 을 이용하여 맥나마 검정을 해보자. 맥나마 검정은 함수 mcnemar.test()를 사용하여 수행할 수 있다.
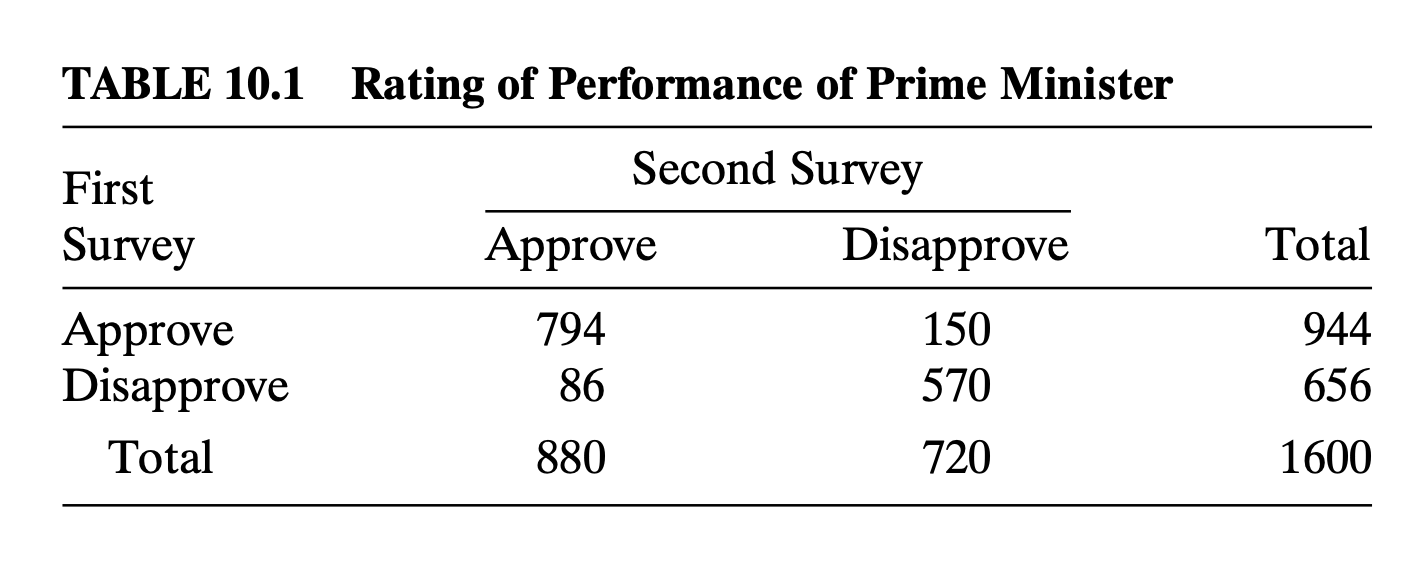
ex3dat <- matrix(c(794,150,86,570),byrow=T,ncol=2)
ex3dat [,1] [,2]
[1,] 794 150
[2,] 86 570mcnemar.test(ex3dat ,correct=F)
McNemar's Chi-squared test
data: ex3dat
McNemar's chi-squared = 17.356, df = 1, p-value = 3.099e-05검정의 p-값이 매우 작으므로 귀무가설을 기각한다. 두 시점에서 수상에 대한 지지율이 하락했다고 할 수 있다. 참고로 첫 번째 조사에서의 지지율의 추정치는 \(\hat p_1=944/1600= 0.59\) 이고 두 번째 조사에서의 지지율의 추정치는 \(\hat p_2=880/1600= 0.55\) 이다. 또한 의견을 바꾸지 않은 사람의 비율은 \((794+570)/1600=0.8225\)로 대부분의 시민들이 지지 의견을 바꾸지 않았다.