library(tidyverse)
library(kableExtra)
library(ggplot2)
library(here)
library(car)
library(lme4)
library(lmerTest)14 교차실험
14.1 필요한 패키지
14.2 교차실험의 개요
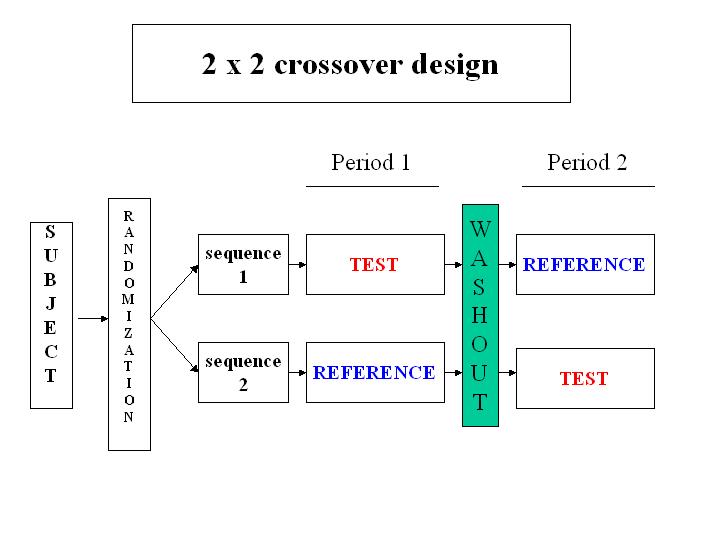
위의 그림은 2 개의 순서(sequence), 2개의 시점(period) 로 구성된 \(2 \times 2\) 교차실험(crossover experiment, crossover desing)의 구조를 나타낸다.
순서(sequence) 는 환자가 처리를 받는 순서(treatment sequence)를 의미하며 기간(period) 는 환자가 처리를 받는 두 시점, 즉 첫번째 치료(period 1)와 두 번째 치료의 시점(period 2)을 의미한다.
교차실험에서는 각 피험자를 임의화 방법을 통하여 2개의 순서 중 하나의 순서에 임의로 배정하여 두 가지 서로 다른 치료를 정해진 순서에 따라서 받는다. 위의 그림 14.1 에서 첫 번째 순서(sequence 1)에 배정된 환자는 첫 번째 시점에서 TEST 처리를 받고 약물의 성분이 신체에서 모두 빠져나가는 기간(washout period; 세척기간)을 가진 후에 두 번째 시점에서는 REFERENCE 처리를 받는다. 반대로 두 번째 순서(sequence 2)에 배정된 환자는 첫번째 시점에서 REFERENCE 처리를 받고 두 번째 시점에서는 TEST 처리를 받는다. 따라서 반응변수은 각 피험자에 대해 두 번 반복 측정된다.
교차 실험는 치료가 완치에 영향을 미치지 않고 상태를 완화하는 치료, 즉 만성 질환에 대한 치료 효과를 연구할 때 주로 사용된다. 한 가지 치료에 대한 반응이 측정된 후 치료를 중단하면 피험자가 기존의 상태로 돌아갈 수 있어야 교차실험을 수행할 수 있다.
교차실험에서는 동일한 실험 대상에 대하여 치료법을 비교하기 떄문에적은 표본의 크기로 더 정확한 결과를 얻을 수 있을 것으로 기대할 수 있다. 독립 집단을 비교하는 실험과 비교하면, 한 명의 환자에 대하여 서로 다른 처리를 받은 반응값을 동시에 얻을 수 있으므로 개인의 특성이 제거된 치료 효과를 더 정밀하게 얻을 수 있다. 따라서 독립 집단을 비교하는 실험과 비교할 때, 교차실험에서는 필요한 표본 크기가 작아진다.
하지만, 교차 실험의 통계 분석은 독립 집단을 비교하는 실험보다 더 복잡하며 추가적인 가정이 필요하다. 때로는 치료 효과(treatment effect)를 이전 치료의 이월 효과(carry-over effect)와 분리하기 어려울 수 있다.
또한, 피험자를 최소 두 번 이상 측정해야 하므로 환자를 연구에 계속 참여하게 하는 것이 더 어려울 수 있다. 특히 측정 과정이 불편하거나 시간이 많이 소요되는 경우에는 중도 탈락하는 환자가 많아 질 수 있다.
14.3 교차실험의 모형
교차실험의 통계적 분석에 대한 자세한 내용은 Chow 와/과 Liu (1999) 또는 Jones 와/과 Kenward (2003) 을 참고하자.
먼저, 두 개의 처리 T (TEST) 와 R (REFERENCE) 를 비교하는 실험이라고 가정하자. 또한 각 처리 순서(sequence)에 각각 \(n_1\) 과 \(n_i\) 명의 피험자가 할당되었다고 가정하자.
\(2 \times 2\) 교차실험의 일반적인 통계적 모형은 다음과 같이 나타낼 수 있다.
\[ y_{i j k}= \mu+S_{ik}+p_{j}+f_{(j, k)}+c_{(j-1, k)}+e_{i j k}, \quad i=1, \ldots, n_i, ~~ j=1,2, ~~ k=1,2 \tag{14.1}\]
위의 14.1 식에서 주어진 각 항들의 의미는 다음과 같다.
반응값
\(y_{i j k}\) 는 \(i\) 번째 환자가 \(k\) 번째 순서의 \(j\) 번째 시점(period)에 배정된 치료를 받았을 때의 반응값을 나타낸다.
| Sequence | Period 1 | Period 2 |
|---|---|---|
| \(1\) | \(y_{i11}\) | \(y_{i21}\) |
| \(2\) | \(y_{i12}\) | \(y_{i22}\) |
전체 평균
\(\mu\) 는 전체 평균을 나타낸다.
개인 효과
\(S_{ik}\) 는 \(k\) 번째 순서에 배정된 \(i\) 번째 피험자의 개인적인 효과를 나타내는 임의 효과(random effect)이다.
일반적으로 개인 효과 \(S_{ik}\) 는 평균이 0이고 분산이 \(\sigma^2_{s}\) 인 정규분포를 따른다고 가정한다.
시점 효과
\(p_{j}\) 는 \(j\) 번째 시점(period)의 효과를 나타낸다.
| Sequence | Period 1 | Period 2 |
|---|---|---|
| \(1\) | \(p_1\) | \(p_2\) |
| \(2\) | \(p_1\) | \(p_2\) |
처리 효과
\(f_{(j, k)}\) 는 \(k\) 번째 순서에서 \(j\) 번째 시점에 적용된 처리의 효과를 나타낸다.
| Sequence | Period 1 | Period 2 |
|---|---|---|
| \(1\) | \(f_T\) | \(f_R\) |
| \(2\) | \(f_R\) | \(f_T\) |
처리 효과를 나타내는 \(f_{(j, k)}\) 는 배정된 순서와 시점에 따라 정해지는 효과이다. 예를 들어 그림 14.1 에서 \(f_{(1, 1)}\) 는 T 처리의 효과 \(f_T\) 를 나타내고 \(f_{(2, 1)}\) 는 R 처리의 효과 \(f_R\) 를 나타낸다. 또한 \(f_{(1, 2)}\) 는 R 처리의 효과를 나타내고 \(f_{(2, 2)}\) 는 T 처리의 효과를 나타낸다.
\[ f_{(j, k)}= \begin{cases} f_{T} & \text { if } k=j \\ f_{R} & \text { if } k \neq j\end{cases} \]
이월 효과
\(c_{(j-1, k)}\) 는 환자가 이전 시점에서 받은 처리 효과의 일부가 다음 시점에 영향을 미치는 효과로서 이월 효과(carry-over effect)를 나타낸다.
| Sequence | Period 1 | Period 2 |
|---|---|---|
| \(1\) | \(0\) | \(c_T\) |
| \(2\) | \(0\) | \(c_R\) |
이월 효과를 나타내는 \(c_{(j-1, k)}\) 는 두 번째 시점에서만 나타나는 효과로서 앞에서 받은 처리의 효과가 세척기간(washout period)에서 모두 제거되지 못하고 다음 시점에도 영향을 주는 효과를 나타낸다. 2개의 순서를 비교하면 첫 번째 시점에서 받은 처리 효과가 다르기 때문에 이월 효과도 다르게 나타날 수 있다. 예를 들어 그림 14.1 에서 \(c_{(1, 1)}\) 은 첫 번째 순서의 첫 번째 시점에서 받은 처리의 이월효과를 나타내기 때문에 T 처리의 이월 효과 \(c_T\)를 나타내고 \(c_{(1, 2)}\) 는 R 처리의 이월 효과 \(c_R\) 를 나타낸다.
\[ c_{(j-1, k)}= \begin{cases}c_{T} & \text { if } j=2, k=1 \\ c_{R} & \text { if } j=2, k=2 \\ 0 & \text { otherwise }\end{cases} \]
오차항
\(e_{i j k}\) 는 독립적인 오차항을 나타낸다.
오차항은 독립적이고 평균이 0 이며 분산이 \(\sigma^2_e\) 인 정규분포를 따른다고 가정한다. 또한 오차항 \(e_{i j k}\) 는 개인 효과 \(S_{ik}\) 와 독립이라고 가정한다.
식 14.1 가정 하에서 \(2 \times 2\) 교차 설계에서 나타나는 반응변수 \(y_{ijk}\) 의 평균을 다음 표와 같이 나타낼 수 있다.
\[ E(y_{ijk}) = \mu_{jk} \]
을 다음과 같이 나타낼 수 있다.
| Sequence | Period 1 | Period 2 |
|---|---|---|
| \(1\) | \(\mu_{11}=\mu+p_{1}+f_{T}\) | \(\mu_{21}=\mu+p_{2}+f_{R}+c_{T}\) |
| \(2\) | \(\mu_{12}=\mu+p_{1}+f_{R}\) | \(\mu_{22}=\mu+p_{2}+f_{T}+c_{R}\) |
14.4 효과에 대한 검정
교차실험의 각 효과를 추정하고 비교하기 위하여 다음과 같은 간단한 t-검정 방법을 고려할 수 있다.
14.4.1 이월 효과에 대한 검정
교차실험에서 이월 효과가 존재하면 처리 효과를 추정하기 어려울 수 있다. 만약 첫 번째 시점의 처리 효과가 두 번째 시점에도 영향을 미치는 경우, 즉 이월 효과가 존재하는 경우는 피험자에게 나타난 효과가 그 시점에서 받은 처리 효과인지, 전 시점의 처리 효과가 이월되어 나타난 경우인지 구분하기 어렵기 떄문이다.
따라서 이월 효과를 먼저 추정하고 이월효과가 유의하지 않은 경우 처리 효과를 비교하는 것이 일반적인 절차이다.
이월 효과를 추정하디 위하여 다음과 같은 방법을 고려할 수 있다.
먼저 각 순서에 대하여 환자의 두 반응값들의 합 \(t_{ik}\)
\[ t_{ik} = y_{i1k} + y_{i2k} , \quad k=1,2 \tag{14.2}\]
를 고려하면 모형 14.1 에서 다음과 같이 나타낼 수 있다.
\[ \begin{aligned} t_{i1} &= y_{i11} + y_{i21} \\ & = (\mu + S_{i1} + p_1 + f_T + 0 + e_{i11}) + (\mu + S_{i1} + p_2 + f_R + c_T + e_{i21}) \\ & = 2\mu + 2S_{i1} + p_1 + p_2 + f_T + f_R + c_T + e_{i11} + e_{i21} \\ & = 2\mu + p_1 + p_2 + f_T + f_R + c_T + (2S_{i1} + e_{i11} + e_{i21}) \\ & = 2\mu + p_1 + p_2 + f_T + f_R + c_T + e'_{i1} \\ t_{i2} &= y_{i12} + y_{i22} \\ &= (\mu + S_{i2} + p_1 + f_R + 0 + e_{i12}) + (\mu + S_{i2} + p_2 + f_T + c_R + e_{i22}) \\ &= 2\mu + 2S_{i2} + p_1 + p_2 + f_R + f_T + c_R + e_{i12} + e_{i22} \\ &= 2\mu + p_1 + p_2 + f_R + f_T + c_R + (2S_{i2} + e_{i12} + e_{i22}) \\ &= 2\mu + p_1 + p_2 + f_R + f_T + c_R + e'_{i2} \\ \end{aligned} \tag{14.3}\]
위의 식에서 \(e'_{i1}\) 와 \(e'_{i2}\) 는 각각 오차항들과 개인효과의 조합으로 나타난 새로운 오차항으로 볼 수 있다.
이제 \(t_{i1}\) 와 \(t_{i2}\) 의 각각의 평균 \(\bar t_1\) 과 \(\bar t_2\) 을 구하고, 두 평균의 차이를 \(\bar t\) 라고 하자.
\[ \bar t = \bar t_1 - \bar t_2 \quad \text{ where } ~~\bar t_1 = \frac{1}{n_1} \sum_{i=1}^{n_1} t_{i1} ~~\text{ and }~~ \bar t_2 = \frac{1}{n_2} \sum_{i=1}^{n_2} t_{i2} \] 위의 통계량 \(\bar t\) 의 기대값을 구해보면 14.2 식을 이용하여 다음과 같이 나타낼 수 있다.
\[ \begin{aligned} E(\bar t) & = E(\bar t_1) - E(\bar t_2) \\ & = (2\mu + p_1 + p_2 + f_T + f_R + c_T) - (2\mu + p_1 + p_2 + f_R + f_T + c_R) \\ & = c_T - c_R \end{aligned} \] 따라서 이월 효과 \(c_T - c_R\) 가 존재하는 가설검정을 위하여
\[ H_0: c_T - c_R = 0 \quad \text{ vs. } \quad H_1: c_T - c_R \ne 0 \]
\(\bar t\) 이용한 t-검정을 실시할 수 있다. 이월 효과에 대한 t-검정에서 사용할 통계량은 다음과 같다.
\[ t = \frac{\bar t_1 -\bar t_2}{\sqrt{\hat \sigma^2_t \left ( \frac{1}{n_1} + \frac{1}{n_2} \right )}} \quad \text{ where } ~~ \hat \sigma^2_t = \frac{1}{n_1+n_2-2} \sum_{k=1}^2 \sum_{i=1}^{n_i} (t_{ik} - \bar t_k)^2 \tag{14.4}\]
위에서 구한 검정통계량 \(t\) 값이 \(t_{n_1 + n_2 -2, \alpha/2}\) 보다 크면 이월 효과가 유의하다고 판단할 수 있다. 반대로 \(t\) 값이 \(t_{n_1 + n_2 -2, \alpha/2}\) 보다 작으면 이월 효과가 유의하지 않다고 판단할 수 있으며 이 경우 처리 효과를 비교하는 것이 가능하다.
다만 유의할 점은 이월 효과가 통계적 유의하지 않다고 판단되더라도 이월효과가 존재하지 않는다는 강력한 증거는 아니다. 따라서 이월 효과가 나타나지 않도록 하기 위하여 충분한 세척기간을 두어야 한다.
14.4.2 처리 효과에 대한 검정
처리 효과 \(f_{T}\) 와 \(f_{R}\) 를 추정하기 위하여 다음과 같이 두 그룹을 비교하는 간단한 t-검정 방법을 적용해 보자.
처리 효과 \(f_{T}\) 와 \(f_{R}\) 를 비교하는 경우 이월효과가 없다고 가정한다. 즉
\[ c_T = c_R = 0 \]
먼저 두 처리 효과의 차이 \(\delta = f_{T}-f_{R}\) 를 반영하는 각 개인에 대한 반응값의 차이를 다음과 같이 나타낼 수 있다.
\[ d_{ik} = \frac{y_{i1k} - y_{i2k}}{2}, \quad k=1,2 \tag{14.5}\]
모형 14.1 에서 \(d_{ik}\) 는 각 순서(\(k=1,2\))에 대해서 다음과 같이 나타낼 수 있다.
\[ \begin{aligned} d_{i1} &= \frac{y_{i11} - y_{i21}}{2} \\ & = \frac{1}{2}(\mu + S_i + p_1 + f_T + 0 + e_{i11}) - \frac{1}{2}(\mu + S_i + p_2 + f_R + e_{i21}) \\ & = \frac{1}{2} (p_1 - p_2) + \frac{1}{2} (f_T - f_R) + \frac{1}{2} (e_{i11} - e_{i21}) \\ & = \frac{1}{2}(p_1 - p_2) + \frac{1}{2}(f_T - f_R) + e'_{i1} \\ d_{i2} &= \frac{y_{i12} - y_{i22}}{2} \\ &= \frac{1}{2} (\mu + S_i + p_1 + f_R + 0 + e_{i12}) - \frac{1}{2} (\mu + S_i + p_2 + f_T + e_{i22}) \\ &= \frac{1}{2} (p_1 - p_2) + \frac{1}{2}(f_R - f_T) +\frac{1}{2} (e_{i12} - e_{i22}) \\ &= \frac{1}{2}(p_1 - p_2) + \frac{1}{2}(f_R - f_T) + e'_{i2} \\ \end{aligned} \]
이제 각 순서에 대하여 반응값의 차이 \(d_{ik}\) 의 평균 \(\bar d_1\) 과 \(\bar d_2\) 을 구하고, 두 평균의 차이를 \(\bar d\) 라고 하자.
\[ \bar d = \bar d_1 - \bar d_2 \quad \text{ where } ~~\bar d_1 = \frac{1}{n_1} \sum_{i=1}^{n_1} d_{i1} ~~\text{ and }~~ \bar d_2 = \frac{1}{n_2} \sum_{i=1}^{n_2} d_{i2} \]
위의 통계량 \(\bar d\) 의 기대값을 구해보면 14.2 식을 이용하여 다음과 같이 나타낼 수 있다.
\[ \begin{aligned} E(\bar d) & = E(\bar d_1) - E(\bar d_2) \\ & = \left [ \frac{1}{2}(p_1 - p_2) + \frac{1}{2}(f_T - f_R) \right ]- \left [ \frac{1}{2}( p_1 - p_2) + \frac{1}{2}(f_R - f_T ) \right ]\\ & = f_T - f_R \end{aligned} \] 따라서 두 개의 처리 효과 유의하게 다른지에 대한 가설검정을 위하여
\[ H_0: f_T - f_R = 0 \quad \text{ vs. } \quad H_1: f_T - f_R \ne 0 \]
\(\bar d\) 이용한 t-검정을 실시할 수 있다. 처리 효과에 대한 t-검정에서 사용할 통계량은 다음과 같다.
\[ t = \frac{\bar d_1 -\bar d_2}{\sqrt{\hat \sigma^2_d \left ( \frac{1}{n_1} + \frac{1}{n_2} \right )}} \quad \text{ where } ~~ \hat \sigma^2_d = \frac{1}{n_1+n_2-2} \sum_{k=1}^2 \sum_{i=1}^{n_i} (d_{ik} - \bar d_k)^2 \tag{14.6}\]
위에서 구한 검정통계량 \(t\) 값이 \(t_{n_1 + n_2 -2, \alpha/2}\) 보다 크면 두 처리 효과에 유의한 차이를 있다고 판단할 수 있다.
14.5 교차실험 예제
14.5.1 간단한 예제
다음은 간단한 교차실험의 예제이다.
다음 자료는 첫 번째 처리 순서(S1)에 배정된 5명의 환자는 첫 번쨰 시점(P1)에서 A 처리를 받고 두 번째 시점(P2)에서 B 처리를 받았다. 두 번째 처리 순서(S2)에 배정된 5명의 환자는 첫 번쨰 시점(P1)에서 B 처리를 받고 두 번째 시점(P2)에서 A 처리를 받았다.
| Group | P1 | P2 |
|---|---|---|
| S1 | A |
B |
| S2 | B |
A |
df_ex1 Subject Group P1 P2
1 1 S1 9 9
2 2 S1 10 7
3 3 S1 13 10
4 4 S1 10 10
5 5 S1 10 10
6 6 S2 12 12
7 7 S2 9 17
8 8 S2 4 15
9 9 S2 9 13
10 10 S2 7 18이제 14.2 과 14.5 에 제시된 이월효과에 대한 검정에 필요한 반응값의 합 \(t_{ik}\) 과 반응값의 차이 \(d_{ik}\) 를 계산하여 데이터프레임에 포함시키지.
df_ex1 <- df_ex1 %>%
dplyr::mutate(t = P1 + P2, d = (P1 - P2)/2)
df_ex1 Subject Group P1 P2 t d
1 1 S1 9 9 18 0.0
2 2 S1 10 7 17 1.5
3 3 S1 13 10 23 1.5
4 4 S1 10 10 20 0.0
5 5 S1 10 10 20 0.0
6 6 S2 12 12 24 0.0
7 7 S2 9 17 26 -4.0
8 8 S2 4 15 19 -5.5
9 9 S2 9 13 22 -2.0
10 10 S2 7 18 25 -5.5다음으로 반응값의 합 \(t_{ik}\) 과 반응값의 차이 \(d_{ik}\) 에 대한 기술통계량을 살펴보자.
df_ex1 %>%
group_by(Group) %>%
summarise(n=n(), mean_t = mean(t), var_t = var(t),
mean_d = mean(d), var_d = var(d))# A tibble: 2 × 6
Group n mean_t var_t mean_d var_d
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 S1 5 19.6 5.3 0.6 0.675
2 S2 5 23.2 7.7 -3.4 5.68 위의 기술 통계량은 다음과 같이 계산할 수 있다.
\[ \begin{aligned} \bar t_1 & = \frac{18+17+23+20+20}{5} = 19.6 \\ \bar t_2 & = \frac{24+26+19+22+25}{5} = 23.2 \\ s^2_{t1} & = \frac{ (18-19.6)^2 + (17-19.6)^2 + (23-19.6)^2 + (20-19.6)^2 + (20-19.6)^2}{4} = 5.3 \\ s^2_{t2} & = \frac{ (24-23.2)^2 + (26-23.2)^2 + (19-23.2)^2 + (22-23.2)^2 + (25-23.2)^2}{4} = 7.7 \\ \end{aligned} \]
\[ \begin{aligned} \bar d_1 & = \frac{1}{5} (0 + 1.5 + 1.5 + 0 + 0) = 0.6 \\ \bar d_2 & = \frac{1}{5} (0 + (-4) + (-5.5) + (-2) + (-5.5)) = -3.4 \\ s^2_{d1} & = \frac{ (0-0.6)^2 + (1.5-0.6)^2 + (1.5-0.6)^2 + (0-0.6)^2 + (0-0.6)^2}{4} = 0.675 \\ s^2_{d2} & = \frac{ (0+5.3)^2 + (-4+5.3)^2 + (-5.5+5.3)^2 + (-2+5.3)^2 + (-5.5+5.3)^2}{4} = 5.675 \\ \end{aligned} \]
먼저 이월효과의 유무에 대한 가설 검정을 위하여 제시된 14.4 에서 검정 통계량은 다음과 같이 계산할 수 있다.
\[ \begin{aligned} t & = \frac{\bar t}{\sqrt{\hat \sigma^2_t \left ( \frac{1}{n_1} + \frac{1}{n_2} \right )}} \\ & = \frac{\bar t_1 - \bar t_2}{\sqrt{\hat \sigma^2_t \left ( \frac{1}{5} + \frac{1}{5} \right )}} \\ & = \frac{19.6-23.2}{\sqrt{ (6.5) \left ( \frac{1}{5} + \frac{1}{5} \right )}} \\ & = -2.23 \end{aligned} \] 위에서
\[ \hat \sigma^2_t = \frac{1}{n_1+n_2-2} \sum_{k=1}^2 \sum_{i=1}^{n_i} (t_{ik} - \bar t_k)^2 = \frac{1}{5+5-2} [ (4)(5.3) + (4)(7.7)] = 6.5 \]
따라서 t-통계량의 절대값 \(|t| = 2.23\) 이 \(t_{8, 0.025} = 2.306\) 보다 작으므로 이월효과가 유의하지 않다고 판단할 수 있다.
위의 결과는 다음과 같이 R 의 함수 t.test 를 사용하여 얻을 수 있다. 이월효과 검정에 대한 p-값은 \(p=0.05607\) 이다.
t.test(t ~ group, var.equal = TRUE, data = df_ex1)
Two Sample t-test
data: t by group
t = -2.2326, df = 8, p-value = 0.05607
alternative hypothesis: true difference in means between group S1 and group S2 is not equal to 0
95 percent confidence interval:
-7.3183199 0.1183199
sample estimates:
mean in group S1 mean in group S2
19.6 23.2 이제 처리 A 와 B 의 효과 차이에 대한 검정을 실시해보자. 첫 번째 처리 순서에는 A->B, 두 번째 처리 순서에서는 B->A 의 순서로 실험을 수행하여으므로 위의 기초통계량에서 \(\bar d = \bar d_1 - \bar d_2\) 은 A 처리 효과 \(f_A\) 와 B 처리의 차이 효과 \(f_B\) 의 차이를 나타낸다.
\[ f_A - f_B \approx \bar d_1 -\bar d_2 = 0.6 - (-3.4) = 4 \]
처리 효과에 대한 가설검정을 위하여 제시된 14.6 에서 검정 통계량은 다음과 같이 계산할 수 있다.
\[ \begin{aligned} t & = \frac{\bar d}{\sqrt{\hat \sigma^2_d \left ( \frac{1}{n_1} + \frac{1}{n_2} \right )}} \\ & = \frac{\bar d_1 - \bar d_2}{\sqrt{\hat \sigma^2_d \left ( \frac{1}{5} + \frac{1}{5} \right )}} \\ & = \frac{0.6 - (-3.4)}{\sqrt{ (3.175) \left ( \frac{1}{5} + \frac{1}{5} \right )}} \\ & = 3.55 \end{aligned} \]
위에서 \[ \hat \sigma^2_d = \frac{1}{n_1+n_2-2} \sum_{k=1}^2 \sum_{i=1}^{n_i} (d_{ik} - \bar d_k)^2 = \frac{1}{5+5-2} [ (4)(0.675) + (4)(5.675)] = 3.175 \]
따라서 t-통계량의 절대값 \(|t| = 3.55\) 이 \(t_{8, 0.025} = 2.306\) 보다 크므로 처리 효과가 유의하다고 판단할 수 있다.
위의 결과는 다음과 같이 R 의 함수 t.test 를 사용하여 얻을 수 있다. 처리효과 검정에 대한 p-값은 \(p=0.007516\) 이다.
t.test(d ~ group, var.equal = TRUE, data = df_ex1)
Two Sample t-test
data: d by group
t = 3.5494, df = 8, p-value = 0.007516
alternative hypothesis: true difference in means between group S1 and group S2 is not equal to 0
95 percent confidence interval:
1.401265 6.598735
sample estimates:
mean in group S1 mean in group S2
0.6 -3.4 14.5.2 폐질환 환자의 교차실험
예제에 사용된 자료는 Jones 와/과 Kenward (2003) 2장에서 제시된 예제를 사용하였다.
시용된 데이터는 하나의 병원에서 실험함 자료이며 무작위 배정(randomized), 위약 대조(placebo-controlled), 이중 맹검 연구(double blinded) 실험에서 얻은 데이터이다.
실험의 목적은 만성 폐쇄성 폐질환(Chronic Obstructive Pulmonary Diseasel; COPD) 환자에 대하여 하루에 두 번 투여하는 흡입 약물(inhaler)인 메타콜린(A)의 효능과 안전성을 평가하기 위한 자료이다.
실험에 참가할 수 있는 기준(inlcusion criteria)을 충족한 환자는 2주간 병원에 2번을 방문하여 치료 전단계(rin-in period)를 거치는데 다양한 알레지 반응에 대한 시험을 받고 임상 시험에 참가할 수 있는지 검사한다.
임상시험에 참가할 수 있는 자격이 되는 환자는 병원을 방문하여 메타콜린(A) 또는 그에 상응하는 위약(B) 중 하나를 무작위로 배정하고 4주 동안 약물을 투여하는 치료를 받는다(첫 번쨰 시점; period 1). 4주 치료가 끝난 환자들은 다시 4주 동안 다른 약물로 치료를 받는다(두 번째 시점; period 2).
| Group | resp1 | resp2 |
|---|---|---|
| 1 | A |
B |
| 2 | B |
A |
주요 반응 변수(primary efficacy variable or primary reponse variable)은 아침에 측정한 최고날숨속도(Peak Expiratory Flow Rate; PEFR)이며 매일 아침에 일어나서, 약을 복용하기 전, 취침 시간에 3번 측정한다.
연구에 모집된 총 77명의 환자 중 66명이 무작위로 치료에 배정되었다. 각 치료 순서(sequence; AB 그룹 또는 BA 그룹)당 33명을 배정하였다. 최종적으로 56명의 환자(AB 그룹 27명, BA 그룹 29명)의 평균 아침 PEFR에 대한 데이터를 얻었다.
아래 데이터프레임 cross_df 는 실험에 참가한 환자들의 데이터를 나타낸다. 다음은 각 변수에 대한 설명이다.
group: 치료 순서(AB = 1, BA = 2)subject: 각 그룹에서 환자의 순서patno: 환자 번호resp1: 첫 번째 시점에서의 PEFRresp2: 두 번째 시점에서의 PEFRbase: 치료 전 PEFR
cross_df <- read.csv(here::here("data","jones-kenward-data-1.csv"), sep="", header=TRUE) %>%
dplyr::select(-base.)
head(cross_df) group subject patno resp1 resp2
1 1 1 7 121.905 116.667
2 1 2 8 218.500 200.500
3 1 3 9 235.000 217.143
4 1 4 13 250.000 196.429
5 1 5 14 186.190 185.500
6 1 6 15 231.563 221.842먼저 자료에 대한 기술통계량을 살펴보자.
cross_df %>%
group_by(group) %>%
summarise(n=n(), mean_resp1 = mean(resp1), var_resp1 = var(resp1),
mean_resp2 = mean(resp2), var_resp2 = var(resp2))# A tibble: 2 × 6
group n mean_resp1 var_resp1 mean_resp2 var_resp2
<int> <int> <dbl> <dbl> <dbl> <dbl>
1 1 27 246. 6852. 239. 6674.
2 2 29 216. 5275. 230. 5467.다음으로 자료에 대한 그림을 통한 시각적 분석을 위하여자료를 긴 형태(long format)로 변환하자. pivot_longer 함수를 사용하여 시점을 나타내는 변수 period 와 처리를 나타나는 변수 treat 를 생성하고 데이터를 긴 형태로 변환하자.
# make long format data buy creating a period variable
cross_df_long <- cross_df %>%
dplyr::select(group, patno, resp1, resp2) %>%
pivot_longer(cols = c(resp1, resp2), names_to = "period", values_to = "PEFR") %>%
mutate(treat = case_when(group == 1 & period == "resp1" ~ "A",
group == 1 & period == "resp2" ~ "B",
group == 2 & period == "resp1" ~ "B",
group == 2 & period == "resp2" ~ "A"))
head(cross_df_long)# A tibble: 6 × 5
group patno period PEFR treat
<int> <int> <chr> <dbl> <chr>
1 1 7 resp1 122. A
2 1 7 resp2 117. B
3 1 8 resp1 218. A
4 1 8 resp2 200. B
5 1 9 resp1 235 A
6 1 9 resp2 217. B 처리 순서 그룹별로 환자의 첫 번째 시점과 두 번째 시점에서 얻은 PEFR 의 값을 나타내는 프로파일 그림(profile plot)으로 그려보자
#profile plot for each patient in each group
cross_df_long %>%
ggplot(aes(x = period, y = PEFR, group=patno, color = factor(patno))) +
geom_line() +
facet_wrap(~group) 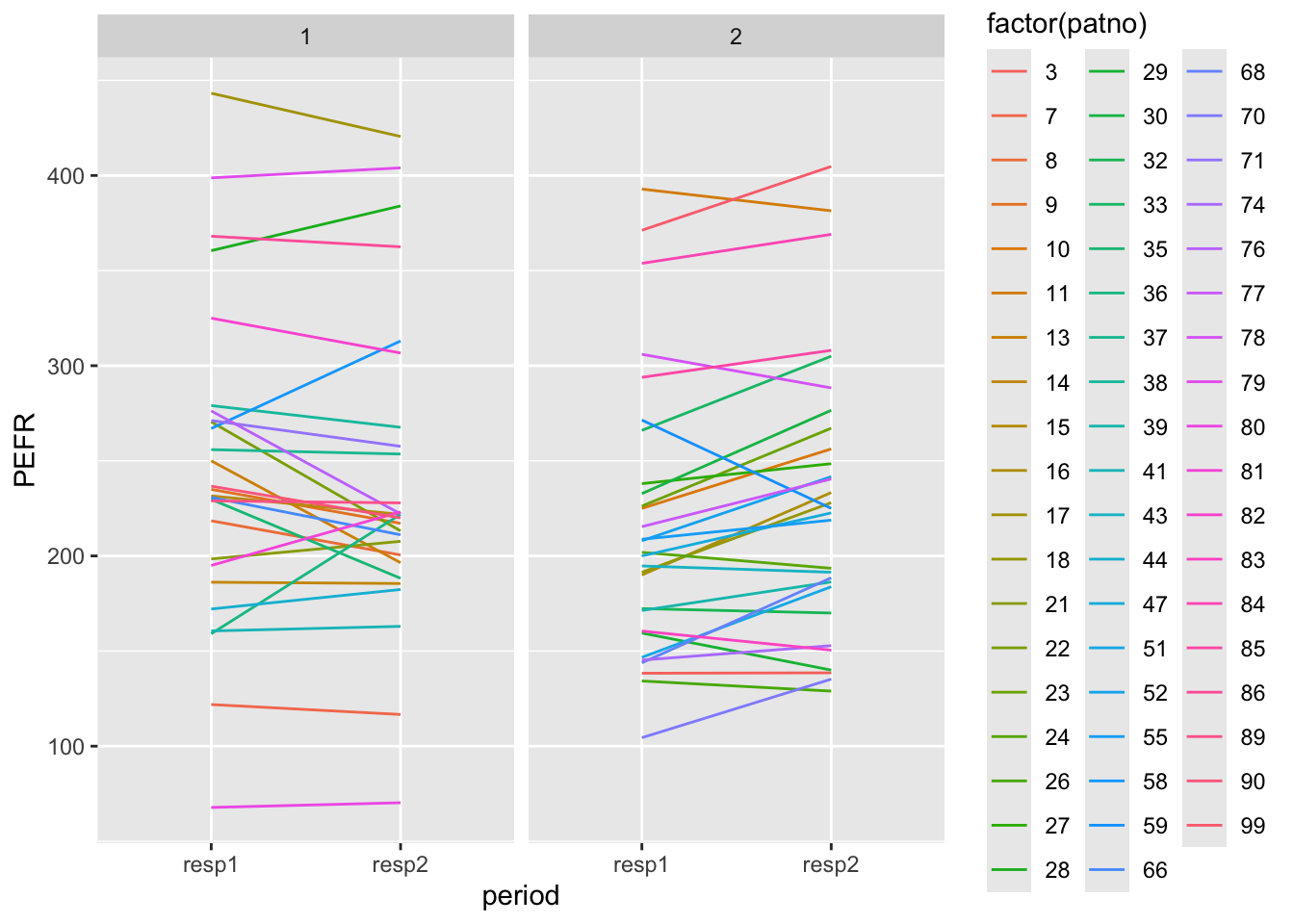
다음으로 처리 순서 그룹별로 첫 번째 시점과 두 번째 시점에서 얻은 반응값 PEFR 의 분포를 상자그림으로 그려보자
# compare the distribution of PEFR at each period by group using boxplot
cross_df_long %>%
ggplot(aes(x = period, y = PEFR, fill = treat)) +
geom_boxplot() +
facet_wrap(~group)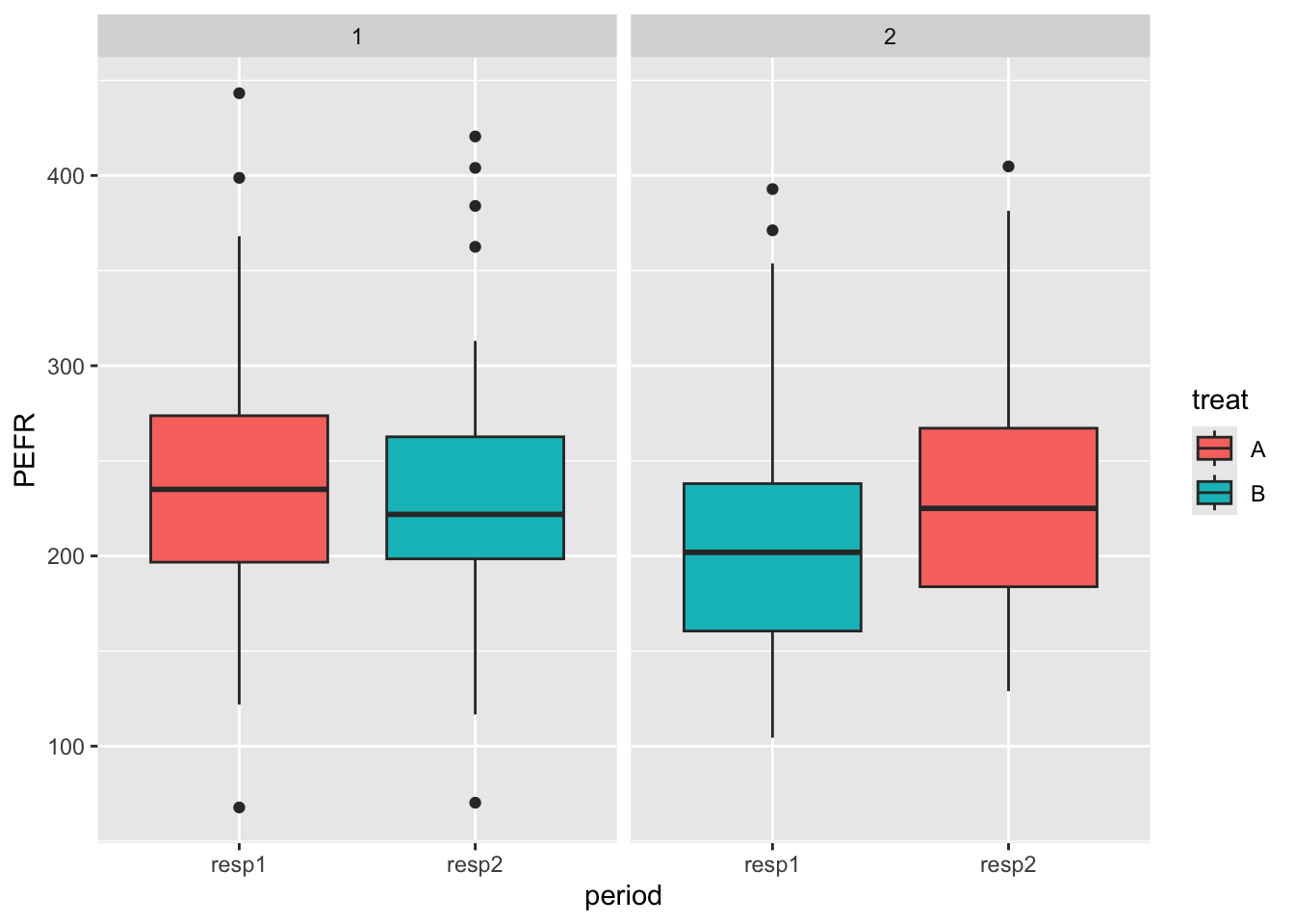
다음으로 교차실험에 대한 분석을 수행하자. 먼저 이월효과가 통계적으로 유의한자에 대한 t-검정을 실시하자. 14.2 와 같이 각 환자의 두 반응값에 대한 합을 구하고 순서 그룹별로 이월효과에 대한 차이를 비교하는 t-검정을 수행하자. 다음 R 코드는 환자의 두 반응값에 대한 합 t 을 계산한 후 순서 그룹 group 간에 t 의 평균이 차이가 있는지 14.4 에 나타난 t-검정을 수행한다.
cross_df <- cross_df %>%
dplyr::mutate(t = resp1 + resp2)
head(cross_df) group subject patno resp1 resp2 t
1 1 1 7 121.905 116.667 238.572
2 1 2 8 218.500 200.500 419.000
3 1 3 9 235.000 217.143 452.143
4 1 4 13 250.000 196.429 446.429
5 1 5 14 186.190 185.500 371.690
6 1 6 15 231.563 221.842 453.405cross_df %>%
group_by(group) %>%
summarise(n=n(), mean_t = mean(t), var_t = var(t))# A tibble: 2 × 4
group n mean_t var_t
<int> <int> <dbl> <dbl>
1 1 27 485. 26288.
2 2 29 446. 20937.t.test(t ~ group, var.equal = TRUE, data = cross_df)
Two Sample t-test
data: t by group
t = 0.94831, df = 54, p-value = 0.3472
alternative hypothesis: true difference in means between group 1 and group 2 is not equal to 0
95 percent confidence interval:
-43.32831 121.10522
sample estimates:
mean in group 1 mean in group 2
485.0421 446.1536 위의 결과를 보면 p-값이 \(0.3472\) 이므로 이월효과가 통계적으로 유의하지 않다고 판단할 수 있다. 따라서 이월효과가 없다고 가정하고 처리 효과에 대한 t-검정을 수행할 수 있다.
이제 14.6 와 같이 각 환자의 두 반응값에 대한 차이를 구하고 순서 그룹별로 처리 효과에 대한 차이를 비교하는 t-검정을 수행하자. 다음 R 코드는 환자의 두 반응값에 대한 차이 d 을 계산한 후 순서 그룹 group 간에 d 의 평균이 차이가 있는지 t-검정을 수행한다.
cross_df <- cross_df %>%
dplyr::mutate(d = (resp1 - resp2)/2)
head(cross_df) group subject patno resp1 resp2 t d
1 1 1 7 121.905 116.667 238.572 2.6190
2 1 2 8 218.500 200.500 419.000 9.0000
3 1 3 9 235.000 217.143 452.143 8.9285
4 1 4 13 250.000 196.429 446.429 26.7855
5 1 5 14 186.190 185.500 371.690 0.3450
6 1 6 15 231.563 221.842 453.405 4.8605cross_df %>%
group_by(group) %>%
summarise(n=n(), mean_d = mean(d), var_d = var(d))# A tibble: 2 × 4
group n mean_d var_d
<int> <int> <dbl> <dbl>
1 1 27 3.32 191.
2 2 29 -7.08 137.t.test(d ~ group, var.equal = TRUE, data = cross_df)
Two Sample t-test
data: d by group
t = 3.0456, df = 54, p-value = 0.003587
alternative hypothesis: true difference in means between group 1 and group 2 is not equal to 0
95 percent confidence interval:
3.554688 17.250478
sample estimates:
mean in group 1 mean in group 2
3.317704 -7.084879 위의 결과를 보면 p-값이 0.0036 이므로 메타콜린(A) 과 위약(B)의 처리 효과가 유의한 차이가 있다는 결론을 내릴 수있다.
메타콜린(A) 와 위약(B)의 처리 효과의 차이는 다음과 같으므로
\[ f_A - f_B \approx \bar d_1 -\bar d_2 = 3.32 -(-7.08) = 10.4 \]
메타콜린(A) 을 복용한 환자들이 위약(B)을 복용한 환자들보다 평균 PEFR 값이 10.4 더 높다고 해석할 수 있다.
14.5.3 생물학적 동등성 실험
예제에 사용된 자료는 Chow 와/과 Liu (1999) 3장에서 제시된 예제를 사용하였다.
생물학적 동등성 실험(bioequivalence study)은 두 개의 약물이 동등한 생물학적 효과를 가지는지를 평가하기 위한 실험이다. 건강한 24 명의 지원자에 대한 각 처리순서에 임의로 12명을 배정하는 \(2\times 2\) 교차실험을 통해 두 개의 약물을 비교하였다. 비교하는 약물은 5개의 50-mg 얄약 형태(test, T) 와 5mL 액체 형태(reference, R) 이다. 반응값은 약을 복용한 후 32시간 동안의 혈장약물 농도에 대한 AUC(Area Under the Curve) 값이다.
| Sequence | P1 | P2 |
|---|---|---|
| 1 | R |
T |
| 2 | T |
R |
아래 데이터프레임 equiv_df 는 실험에 참가한 지원자들의 데이터를 나타낸다. 다음은 각 변수에 대한 설명이다.
Sequence: 치료 순서(RT = 1, TR = 2)patno: 환자 번호P1: 첫 번째 시점에서의 AUCP2: 두 번째 시점에서의 AUC
equv_df <- read.csv(here::here("data","chow-liu-data.csv"), sep="", header=TRUE)
head(equv_df) Sequence patno P1 P2
1 1 1 74.675 73.675
2 1 4 96.400 93.250
3 1 5 101.950 102.125
4 1 6 79.050 69.450
5 1 11 79.050 69.025
6 1 12 85.950 68.700먼저 자료에 대한 기술통계량을 살펴보자.
equv_df %>%
group_by(Sequence) %>%
summarise(n=n(), mean_P1 = mean(P1), var_P1 = var(P1),
mean_P2 = mean(P2), var_P2 = var(P2))# A tibble: 2 × 6
Sequence n mean_P1 var_P1 mean_P2 var_P2
<int> <int> <dbl> <dbl> <dbl> <dbl>
1 1 12 85.8 246. 81.8 389.
2 2 12 78.7 539. 79.3 635.다음으로 자료에 대한 그림을 통한 시각적 분석을 위하여자료를 긴 형태(long format)로 변환하자. pivot_longer 함수를 사용하여 시점을 나타내는 변수 period 와 처리를 나타나는 변수 treat 를 생성하고 데이터를 긴 형태로 변환하자.
# make long format data buy creating a period variable
equv_df_long <- equv_df %>%
dplyr::select(Sequence, patno, P1, P2) %>%
pivot_longer(cols = c(P1, P2), names_to = "period", values_to = "AUC") %>%
mutate(treat = case_when(Sequence == 1 & period == "P1" ~ "R",
Sequence == 1 & period == "P2" ~ "T",
Sequence == 2 & period == "P1" ~ "T",
Sequence == 2 & period == "P2" ~ "R"))
head(equv_df_long)# A tibble: 6 × 5
Sequence patno period AUC treat
<int> <int> <chr> <dbl> <chr>
1 1 1 P1 74.7 R
2 1 1 P2 73.7 T
3 1 4 P1 96.4 R
4 1 4 P2 93.2 T
5 1 5 P1 102. R
6 1 5 P2 102. T 처리 순서 그룹별로 지원지의 첫 번째 시점과 두 번째 시점에서 얻은 AUC 의 값을 나타내는 프로파일 그림(profile plot)으로 그려보자
#profile plot for each patient in each Sequence
equv_df_long %>%
ggplot(aes(x = period, y = AUC, group=patno, color = factor(patno))) +
geom_line() +
facet_wrap(~Sequence) 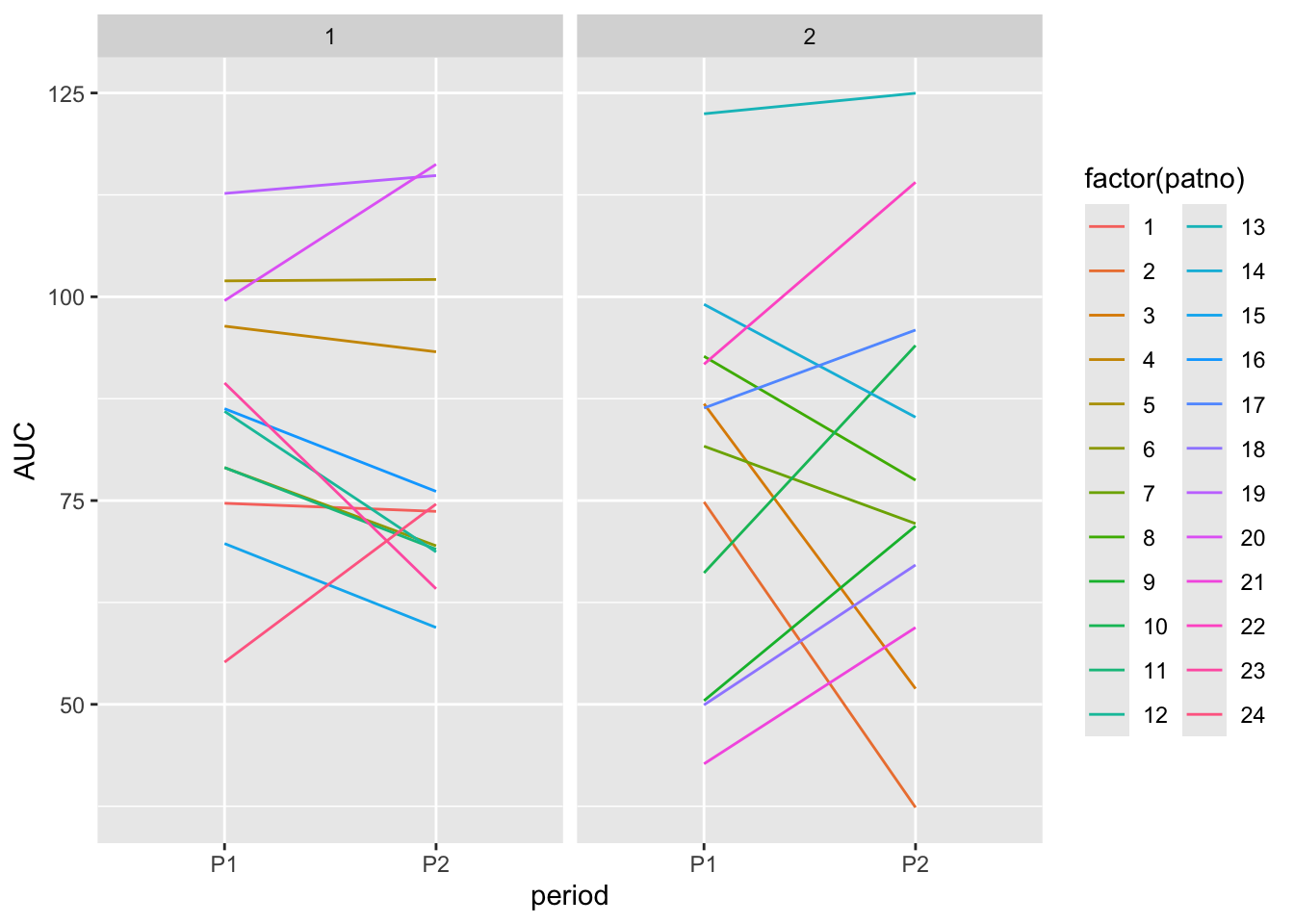
다음으로 처리 순서 그룹별로 첫 번째 시점과 두 번째 시점에서 얻은 반응값 AUC 의 분포를 상자그림으로 그려보자
# compare the distribution of PEFR at each period by Sequence using boxplot
equv_df_long %>%
ggplot(aes(x = period, y = AUC, fill = treat)) +
geom_boxplot() +
facet_wrap(~Sequence)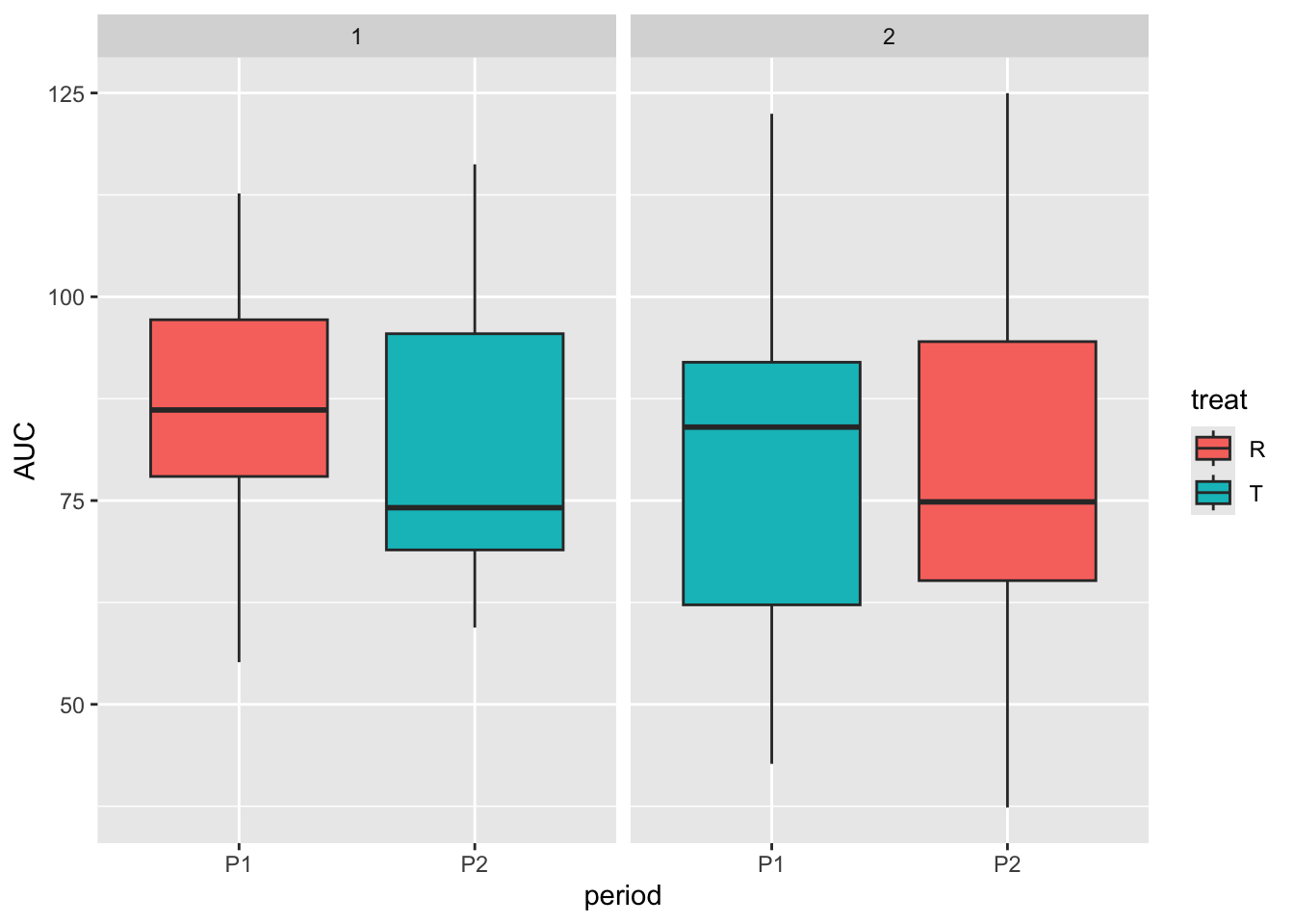
평균적 생물학적동등성에 대한 가설을 고려해보자. 시험약(T)과 대조약(R)간의 반응값의 평균의 차이를 \(\delta\) 라고 하자.
\[ \delta=\mu_T-\mu_R \]
평균적 생물학적 동등성에 대한 가설은 다음과 같다.
\[ H_0: \delta \le \delta_L ~~~or~~~ \delta \ge \delta_U \quad vs. \quad H_1: \delta_L < \delta < \delta_U \tag{14.7}\]
위의 생물학적 동등성에 대한 가설에서 동등성 한계(bioequivalence limit) 인 \(\delta_L\) 과 \(\delta_U\) 는 다음과 같이 주어진다.
\[ \delta_L= - 16.51 \quad \text{and} \quad \delta_U= 16.51 \]
이제 14.6 에 나타난 통계량을 이용하여 각 환자의 두 반응값에 대한 차이를 구하고 순서 그룹별로 처리 효과에 대한 차이에 대한 \(90\%\)-신뢰구간을 구해보자.
유의할 점
생물학적 동등성을 보이기 위한 기준은 \(95\%\) 가 아닌 \(90\%\)-신뢰구간이 \(\delta_L\) 과 \(\delta_U\) 사이에 포함되어야 한다.
처리 순서에 배정된 처리 순서 그룹(
Sequence)에서 첫 번째 순서에서는R->T이고 두 번째 순서에서T->R이다.
따라서 가설 14.7 를 위한 두 반응값에 대한 차이 \(d_{ik}\) 는 다음과 같이 계산할 수 있다.
\[ d_{ik} = \frac{1}{2}(y_{i2k} - y_{i1k}) = \frac{1}{2}({P2} - {P1}), \quad \text{ for } k=1,2\]
다음 R 코드는 환자의 두 반응값에 대한 차이 d 을 계산한 후 평균의 차이에 대한 \(90\%\)-신뢰구간을 구한다.
equv_df <- equv_df %>%
dplyr::mutate(d = (P2 - P1)/2)
head(equv_df) Sequence patno P1 P2 d
1 1 1 74.675 73.675 -0.5000
2 1 4 96.400 93.250 -1.5750
3 1 5 101.950 102.125 0.0875
4 1 6 79.050 69.450 -4.8000
5 1 11 79.050 69.025 -5.0125
6 1 12 85.950 68.700 -8.6250equv_df %>%
group_by(Sequence) %>%
summarise(n=n(), mean_d = mean(d), var_d = var(d))# A tibble: 2 × 4
Sequence n mean_d var_d
<int> <int> <dbl> <dbl>
1 1 12 -2.01 41.2
2 2 12 0.278 126. res <- t.test(d ~ Sequence, var.equal = TRUE, conf.level = 0.9, data = equv_df)
res$conf.int[1] -8.698047 4.123047
attr(,"conf.level")
[1] 0.9위의 결과를 보면 평균의 차이에 대한 \(90\%\)-신뢰구간은 \((-8.698 4.123)\) 으로 \(\delta_L\) 과 \(\delta_U\) 사이에 포함되므로 두 약물의 생물학적 동등성을 보인다고 결론을 내릴 수 있다.
\[(-8.698,~~ 4.123) \subset (-16.51,~~ 16.51)\] 참고로 위에서 구한 \(90\%\)-신뢰구간을 기초 통계량으로 유도해보자.
\[ \begin{aligned} & (\bar d_1 - \bar d_2) \pm t(0.05,22){\sqrt{\hat \sigma^2_d \left ( \frac{1}{n_1} + \frac{1}{n_2} \right )}} \\ & = (-2.01 - 0.278) \pm (1.7171) {\sqrt{(83.6)\left ( \frac{1}{12} + \frac{1}{12} \right )}} \\ & = -2.288 \pm 6.419 \\ & = (-8.698,~~ 4.123) \end{aligned} \]
위에서 \[ \hat \sigma^2_d = \frac{1}{n_1+n_2-2} \sum_{k=1}^2 \sum_{i=1}^{n_i} (d_{ik} - \bar d_k)^2 = \frac{1}{12+12-2} [ (11)(41.2) + (11)(126.)] = 83.6 \]