library(tidyverse)
library(kableExtra)
library(ggplot2)
library(here)
library(car)
library(lme4)
library(lmerTest)8 반복측정자료
8.1 필요한 패키지
8.2 독립표본과 쌍표본
서로 다른 두 처리의 효과(treatment effect)를 비교하기 위하여 주로 사용되는 방법은 두 개의 독립표본(independent sample)을 비교하는 t-검정법이다. 서로 독립인 두개의 집단(구성원이 겹치지 않는 집단)에 서로 다른 처리를 적용한 뒤에 관측된 자료의 표본 평균을 비교하여 두 개의 처리 효과의 차이를 통계적으로 검정하는 방법이다. t-검정을 위한 분포 가정은 다음과 같다.
\[ x_1,x_2, \dots x_{n} \sim_{iid} N(\mu_1, \sigma^2) \quad y_1,y_2, \dots y_{n} \sim_{iid} N(\mu_2, \sigma^2) \]
위의 가정을 다음과 같은 평균모형(mean model)로 표현할 수 있다.
\[ x_i = \mu_1 + e_{i1}, \quad y_i = \mu_2 + e_{i2} \tag{8.1}\]
여기서 \(e_{i1}\)와 \(e_{i2}\)들은 모두 독립이며 \(N(0,\sigma^2)\)을 따르는 오차들이다.
여기서 확률변수 \(x\)와 \(y\)는 서로 독립이고 각 관측값 \(x_1,x_2, \dots x_{n_1}\)과 \(y_1,y_2, \dots y_{n_2}\)들도 각각 모두 독립이다. 분포가정에서 다른 것은 확률변수 \(x\)와 \(y\)의 평균이 다르다.
이러한 가정 하에서 다음의 두개의 가설검정을 할 수 있는 방법이 t-검정법이며
\[ H_0 : \mu_1 = \mu_2 \quad \text{vesus} \quad H_1 : \mu_1 \ne \mu_2 \tag{8.2}\]
검정통계량은 다음과 같이 주어진다.
\[ t = \frac{ \bar x -\bar y} {s_p \sqrt{\tfrac{1}{n} + \tfrac{1}{n}}} \tag{8.3}\]
여기서 \(\bar x\)와 \(\bar y\)는 각 집단의 표본 평균이고 \(s_p^2\)은 합동분산추정량(pooled variance estimator)이다.
\[ s^2_p = \frac{\sum_{i=1}^n (x_i -\bar x)^2 + \sum_{i=1}^n (y_i -\bar y)^2 }{2n-2} \]
이제 두 개의 처리를 비교하는 경우, 독립 표본이 아닌 경우를 고려해 보자.
독립 표본이 아닌 대표적인 경우가 쌍표본(또는 대응표본)에 대한 t-검정이다(paired t-test). 쌍표본 검정에서는 하나의 개체에 두 개의 처리를 모두 적용하여 각 처리에 대한 반응값을 쌍 \((x_i,y_i)\)으로 얻는다. 예를 들어 최초로 허가 받은 약품과 복제약의 생물학적동등성(bioequivalence)을 입증하는 실험에서는 한 사람에게 최초허가약을 투여하여 약의 효과를 보고 일정 시간이 지난 뒤 복제약을 같은 사람에게 투여하여 그 효과를 측정한다. 다른 예로서 두 개의 눈병 치료제를 각각 누에 투여하여 효과를 비교하는 경우도 이러한 쌍표본에 속한다. 넓은 의미에서 일란성 쌍둥이에게 각각 다른 처리를 하여 비교하는 것도 대응비교라고 할 수 있다.
가장 단순한 대응비교로서 각 개체애 대하여 두 개의 처리에 대한 쌍표본 \((x_i,y_i)\)를 관측한다고 가정하자. 이에 대한 분포 모형은 다음과 같다.
\[ d_i = x_i -y_i \sim_{iid} N(\delta,\sigma^2) \text { where } \delta = \mu_1-\mu_2 = E(x)-E(y) \]
대응비교에서 사용되는 t-통계량은 다음과 같다.
\[ t = \frac{ \bar d} {s_d / \sqrt{n}} =\frac{ \bar x -\bar y} {s_d / \sqrt{n}} \tag{8.4}\]
여기서 \(s^2_d\)는 \(d_1,d_2,\dots ,d_n\)의 표본분산이다.
\[ s^2_d = \frac{\sum_{i=1}^n (d_i -\bar d)^2}{n-1} \]
위에서 알아본 독립표본에 의한 비교와 쌍표본에 의한 비교가 다른 점은 무었일까 생각해 보자. 표본의 비교가 다른 개체에서 추출된 독립인 관측치를 이용하는지 또는 같은 개체에서 추출된 대응하는(독립이 아닌) 관측치를 이용하는지에 따라서 서로 다른 t-통계량을 사용한다. 식 8.3 과 식 8.4 에 나타난 t-통계량을 비교하면 분자에 나타난 통계량은 효과의 차이를 나타내는 두 개의 평균의 차이로서 기본적으로 동일하다\((\bar d =\bar x -\bar y)\). 하지만 분모에서는 분자에 나타난 통계량의 표본오차(standard error)를 나타내는 양으로서 서로 다르다. 독립표본에서는 표본의 평균이 서로 독립이므로 다음과 같이 평균의 차이에 대한 분산이 각각의 분산의 합과 같으므로 이에 대한 추정량으로서 합동분산추정량을 이용하였다.
\[
Var(\bar x - \bar y) = Var(\bar x) + Var(\bar y)
\tag{8.5}\]
쌍표본에서는 위의 식 8.5 을 적용할 수 없다. 왜냐하면 두개의 표본 평균이 서로 독립이 아닐 가능성이 매우 높기 때문이다. 같은 개체에서 나온 관측치는 어떠한 형태로든 서로 관계가 있을 가능성이 높기 때문에 독립을 함부로 가정할 수 없다. 예를 들어 생물학적동등성 실험에서는 약 효과의 차이보다 약이 몸에 흡수되는 개인적인 체질이 관측값에 더 큰 영향을 줄 수 있다.
확률변수 \(x\)와 \(y\)가 독립이 아닌 경우 두 모형균의 차이를 비교하기 위하여 비교에 사용된 통계양은 두 확률변수의 차이다. \[ d_i = x_i - y_i \] 여기서 두 개의 확률변수의 차이를 이용할 때 암시적인 가정은 두 개의 확률변수의 차이를 내면 두 변수에 공통적으로 포함된 개인의 특성이 서로 상쇄되어 처리의 차이만이 확률변수 \(d_i\)에 존재한다는 것이다. 지금 설명한 대응비교 모형의 합리적인 가정을 요약하면 다음과 같다.
- 개인의 특성을 반영하는 공통 요인이 두 변수에 모두 영향을 미친다.
- 따라서 두 관측값 \((x_i,y_i)\)가 독립이 아니다
- 두 관측값의 차이를 내면 공통요인이 서로 상쇄되어 처리효과만 남는다.
\[ E(d_i) = \mu_1 - \mu_2 \]
위의 가정을 구현할 수 있는 대응비교 모형을 다음과 같은 가법모형(additive models)로 표현할 수 있다.
\[ x_i = \mu_1 + a_i + e_{i1}, \quad y_i = \mu_2 + a_i + e_{i2} \tag{8.6}\]
여기서 \(a_i\)는 두 확률변수 \((x_i,y_i)\)에 공통으로 포함된 개인적인 특성을 나타내는 요인이며 위의 식 8.6 는 식 8.1 에 공통요인 \(a_i\)가 추가된 형태이다.
두 확률변수 \((x_i,y_i)\)가 종속이기 위해서는 다음과 같은 가정을 이용할 수 있다.
\[ a_i \sim N(0, \sigma^2_a), \quad e_{i1} \sim_{iid} N(0, \sigma^2_e) \quad e_{i2} \sim_{iid} N(0, \sigma^2_e) \]
여기서 \(a_i\)가 평균이 0이고 분산이 \(\sigma_a^2\) 인 확률변수이다. 이러한 요인을 임의효과(random effect)라고 하며 모수(parameter)인 평균 \(\mu_i\)은 고정효과(fixed effect)라고 부른다. \(e_{i1}\)와 \(e_{i2}\)들은 모두 독립이며 평균이 \(0\) 이고 분산이 \(\sigma^2_e\)인 정규분포를 따르는 오차들이다. 또한 \(a_i\)와 (\(e_{i1}\),\(e_{i2}\))도 독립이다.
위와 같은 가정에서 두 변수의 차이를 내면 공통요인인 \(a_i\)가 제거되어 두 처리의 차이만이 남게되며 \(x_i\)와 \(y_i\)는 분포의 가정상 독립이 아니다.
\[ \begin{aligned} d_i & = x_i -y_i \\ & = \mu_1+ a_i + e_{i1} -(\mu_2+ a_i + e_{i2}) \\ & = \mu_1 -\mu_2 +(e_{i1}-e_{i2}) \\ & = \mu_1 -\mu_2 +e^*_i \\ Cov(x_i,y_i) & = Cov(\mu_1+ a_i + e_{i1},\mu_2+ a_i + e_{i2}) \\ & = Cov(a_i, a_i) \\ & = Var(a_i) \\ & = \sigma^2_a \end{aligned} \]
다음 절에서는 여기서 논의한 독립표본과 쌍표본의 개념 및 추정법을 일반적인 선형모형으로 확장하여 체계적인 비교를 해볼것이다.
8.3 일원배치 모형
8.3.1 고정효과 모형
먼저 일원배치 요인계획(one-way factor design)이용한 실험을 생각해 보자. 고려하는 요인의 수준의 개수를 \(I\)라고 하면 \(I\)개의 수준 중에 하나를 임의로 선택하여 실험대상에 적용하는 임의화 방법으로 각 수준마다 \(J\)의 관측값을 얻어다고 하자. 다음과 같은 ANOVA모형을 고려하여 분석을 할 수 있다.
\[ y_{ij} = \mu + \alpha_i + e_{ij}, \quad i=1,2,\dots,I \text{ and } j=1,2,\dots, J \tag{8.7}\]
여기서 \(e_{ij}\)는 서로 독립이며 \(N(0,\sigma_e^2)\)를 따르는 오차항이다.
ANOVA 모형 8.7 에서 \(\mu\)와 \(\alpha_i\)는 고정효과(fixed effect)라고 부르며 추정해야 할 모수(parameter)이다. 세심하게 설계된 실험에서는 수준에 대한 효과 \(\alpha_i\)의 값이 변하지 않게 통제할 수 있는 실험 환경이 가능하다고 생각할 수 있으므로 \(\alpha_i\)의 값을 변하지 않는 고정효과로 보는 것이 합리적이다.
일원배치 요인계획을 이용한 실험에서는 주요 관심사가 수준간의 차이가 있는지에 대한 것이며 이는 제곱합을 이용한 ANOVA table에서 F-test를 이용하여 검정할 수 있다.
\[ H_0: \alpha_1 = \alpha_2 =\dots = \alpha_I \]
8.3.2 혼합효과 모형
이제 다음과 같은 자료의 추출을 생각해 보자. 서울시 A구에 초등학교가 20개있다고 하자. 20개의 학교중 6개의 학교를을 임의로 추출하고 추출된 학교에 속한 모든 6학년 학생들에게 과학시험을 보게하여 점수를 얻었다. 이러한 자료에서 학생들의 성적은 모두 같지 않을 것이 당연하며 가장 점수가 낮은 학생부터 높은 학생까지 점수의 변동(variation)이 존재한다. 변동의 요인은 무었일까? 학생의 개인의 차이(예:학생의 지능, 노력 정도, 학습 환경)도 변동의 요인이지만 또한 학교의 차이도 변동의 요인이 될 수 있다.
여기서 학교에 대한 요인은 앞 절에서 본 실험 자료에서 나타나는 고정 효과에 의한 요인과는 성격이 틀리다. 20개의 학교라는 모집단에서 6개의 학교가 추출되었으며 이 때 학교의 차이는 설계된 실험에서는 수준에 대한 효과와는 다르게 표본 추출 때문에 생기는 변동이라고 할 수 있다. 또한 같은 학교에 다니는 학생들은 같은 지역과 교사 등 공통적인 요인에 의하여 영향을 받는다고 가정할 수 있다. 따라서 같은 학교에 다는 학생들의 성적이 독립이 아닐 수도 있다.
이러한 효과를 임의효과(random effect)라고 부르며 학생들의 과학점수에 대한 모형을 다음과 같은 혼합효과모형(mixed effects model)으로 설명할 수 있다.
\[ y_{ij} = \mu + a_i + e_{ij}, \quad i=1,2,\dots,I \text{ and } j=1,2,\dots, J \tag{8.8}\]
여기서 \(a_i\)는 학교의 효과를 나타내는 임의효과이며 서로 독립이고 \(N(0,\sigma_a^2)\)를 따른다. 또한 개인에 대한 효과 또는 오차항 \(e_{ij}\)는 서로 독립이며 \(N(0,\sigma_e^2)\)를 따른다. 임의효과 \(a_i\)와 오차항 \(e_{ij}\)는 서로 독립이다. 고정효과 \(\mu\)는 전체 평균을 나타내는 모수이다. 학교를 추출할 때 그 효과를 분산이 \(\sigma^2_a\)를 가지는 정규모집단에서 추출한다고 가정하는 것이다. 학교를 하나의 군집(cluster)로 생각하고 학교의 효과를 군집효과로 보고 총변동을 설명하고 나머지 변동은 오차의 변동으로 개인의 효과 등으로 설명한다.
\[ Var(y_{ij}) =Var(\mu + a_i + e_{ij}) = Var(a_i) + Var(e_{ij}) = \sigma^2_a + \sigma^2_e \]
식 8.8 로 표현된 임의효과를 포함한 혼합모형(일원배치 임의효과 모형; one-way random effect models)의 가장 큰 특징 중에 하나는 같은 군집에 속하는 관측치들은 서로 독립이 아니며 양의 상관관계가 있다. 위의 예제에서 두 학생 \(j\)와 \(k\)가 같은 학교 \(i\)에 속한다면
\[ Cov(y_{ij},y_{ik}) = Cov( \mu + a_i + e_{ij}, \mu + a_i + e_{ik}) =Cov (a_i, a_i)=\sigma^2_a \] 따라서
\[ corr(y_{ij},y_{ik})= \frac{ Cov(y_{ij},y_{ik})}{\sqrt{Var(y_{ij})Var(y_{ik})} } = \frac{\sigma^2_a }{\sigma^2_a + \sigma^2_e } \]
위의 상관계수를 보면 학교간의 변동의 크기를 나타내는 \(\sigma^2_a\)각 개인간의 변동을 나타내는 \(\sigma^2_e\)보다 상대적으로 클수록 상관계수가 1에 가까와진다. 보통 \(\sigma^2_a\)을 집단간 변동(between-group variance)라 하고 \(\sigma^2_e\)를 집단내 변동(within-group variance)라고 한다. 따라서 \(\sigma^2_a\)와 \(\sigma^2_e\)의 상대적인 크기의 차이에 따라 군집내 관측값의 상관관계가 달라진다.
식 8.8 의 임의효과 모형은 임의효과가 2개 이상인 모형으로 학장될 수 있다. 예제에서 학교를 추출하고 학교내에서 학급을 추출하여 추출된 학급내의 학생들이 시험을 보면 다음과 같은 모형을 적용할 수 있다.
\[ y_{ijk} = \mu + a_i + b_{ij} + e_{ijk} \]
위의 모형에서 \(a_i\)는 \(N(0,\sigma^2_a)\)를 따르는 학교에 대한 임의효과, \(b_{ij}\)는 \(N(0,\sigma^2_b)\)를 따르는 학급에 대한 임의효과, \(e_{ijk}\)는 \(N(0,\sigma^2_e)\)를 따르는 학생에 대한 임의효과 또는 오차항으로 생각할 수 있다.
임의효과 모형에 고정효과가 같이 포함되어 있는 모형을 혼합모형(mixed model)이라고 부르며 반응변수의 변동에 영향을 미치는 요인들 또는 예측변수 중에서 임의효과와 고정효과를 구별하여 정하고 동시에 모형에 포함시킬수 있다. 예를 들어서 학교를 선택하여 과학시험을 볼 경우에 학기가 시작할 떄 과학교수법 두가지 중 하나를 임의화해서 각 학교에 배정하여 배정된 교수법으로 학생을 가르친 후에 시험을 보았다면 교수법에 대한 효과는 고정효과로 볼 수 있다. 따라서 다음과 같은 모형을 고려할 수 있다.
\[ y_{ij} = \mu + \tau_{k(i)} + a_i + e_{ij} \tag{8.9}\]
여기서 \(\tau_{k(i)}\)는 \(i\)번째 학교의 교수법에 대한 고정효과이다(교수법이 배정된 결과에 의하여 \(k(i)=1\) 또는 \(k(i)=2\)이 된다). 이 교수법에 대한 고정효과에 대해서는 두 교수법이 차이가 있는 지에 대한 검정이 주요한 관심사일 것이다 (\(H_0: \tau_1=\tau_2\))
고정효과와 임의효과의 표기
고정효과는 보통 모형식에서 그릭 문자(\(\alpha\), \(\beta\))로 표시하고 임의효과는 모형식에서 영어 알파벳 문자(\(a\), \(b\))로 표시한다
8.4 반복측정자료
반복측정자료(longitudinal data, repeated measurements)는 관측단위안에서 여러 개의 관측값을 측정한 자료의 형식을 말한다. 예를 들어 환자가 병원을 여러 번 방문하고 방문시마다 혈압을 측정하였다면 한 명의 환자에서 반복 측정한 자료는 서로 독립이 아니다. 또한 가구조사(household survey)에서 가구원의 취업 여부, 건겅 상태등을 여러 해동안 매년 측정하는 경우 이러한 자료를 패널자료(panel data) 또는 longitudinal 자료라고 한다. 이렇게 하나의 관측단위 안에서 측정한 자료들은 서로 독립이 아닌 특징이 있고 자료를 분석하는 경우 이러한 자료들의 종속구조를 고려하는 모형을 사용하는 것이 적절하다. 이렇게 반복측정자료에서 반복자료들의 공분산구조를 설정하는 통계적 방법들은 다양하지만 대표적으로 쉽게 사용할 수 있는 방법이 임의효과를 포함한 혼합모형을 사용하는 방법이다.
보기 8.1 (트럭운전사의 수면시간) lme4 패키지에 자료인 spleepstudy는 화물트럭 운전사들에 대한 수면부족 현상에 대하여 연구한 자료이다. 18명의 운전자들이 매일 3시간의 수면(부족한 수면)을 하면서 매일 일정한 동작의 반응시간을 10일동안 반복적으로 측정한 자료가 있다. 한명의 운전사에게 10일 동안의 반응에 대한 측정자료 10개가 존재하므로 이는 반복측정 자료이며 이러한 10개의 자료는 독립이 아니다. 일단 자료의 구조를 살펴보자. 반응변수 `Reaction은 반응시간(ms)를 나타내며 설명변수로서 Days는 날짜(\(t=0,1,2,\dots,9\)), Subject 는 운전자의 고유번호를 나타낸다.
library(lme4)
library(lmerTest)
str(sleepstudy)'data.frame': 180 obs. of 3 variables:
$ Reaction: num 250 259 251 321 357 ...
$ Days : num 0 1 2 3 4 5 6 7 8 9 ...
$ Subject : Factor w/ 18 levels "308","309","310",..: 1 1 1 1 1 1 1 1 1 1 ...head(sleepstudy, n = 20) Reaction Days Subject
1 249.5600 0 308
2 258.7047 1 308
3 250.8006 2 308
4 321.4398 3 308
5 356.8519 4 308
6 414.6901 5 308
7 382.2038 6 308
8 290.1486 7 308
9 430.5853 8 308
10 466.3535 9 308
11 222.7339 0 309
12 205.2658 1 309
13 202.9778 2 309
14 204.7070 3 309
15 207.7161 4 309
16 215.9618 5 309
17 213.6303 6 309
18 217.7272 7 309
19 224.2957 8 309
20 237.3142 9 309각 운전자에 대한 10일 간의 반응속도가 시간에 따라 어떻게 변하는 가를 알아보자. 전반적으로 시간이 지나면서 운전자들의 반응시간이 증가하고 있음을 알 수 있다. 또한 개인 별로 반응 시간의 변화와 패턴이 다르다는 것을 알 수 있다.
library(ggplot2)
ggplot(sleepstudy, aes(x = Days, y = Reaction)) +
geom_point(size = 0.5) +
geom_smooth(method = lm, se = FALSE, linewidth = 0.5) +
facet_wrap("Subject", labeller = label_both) +
theme_bw()`geom_smooth()` using formula = 'y ~ x'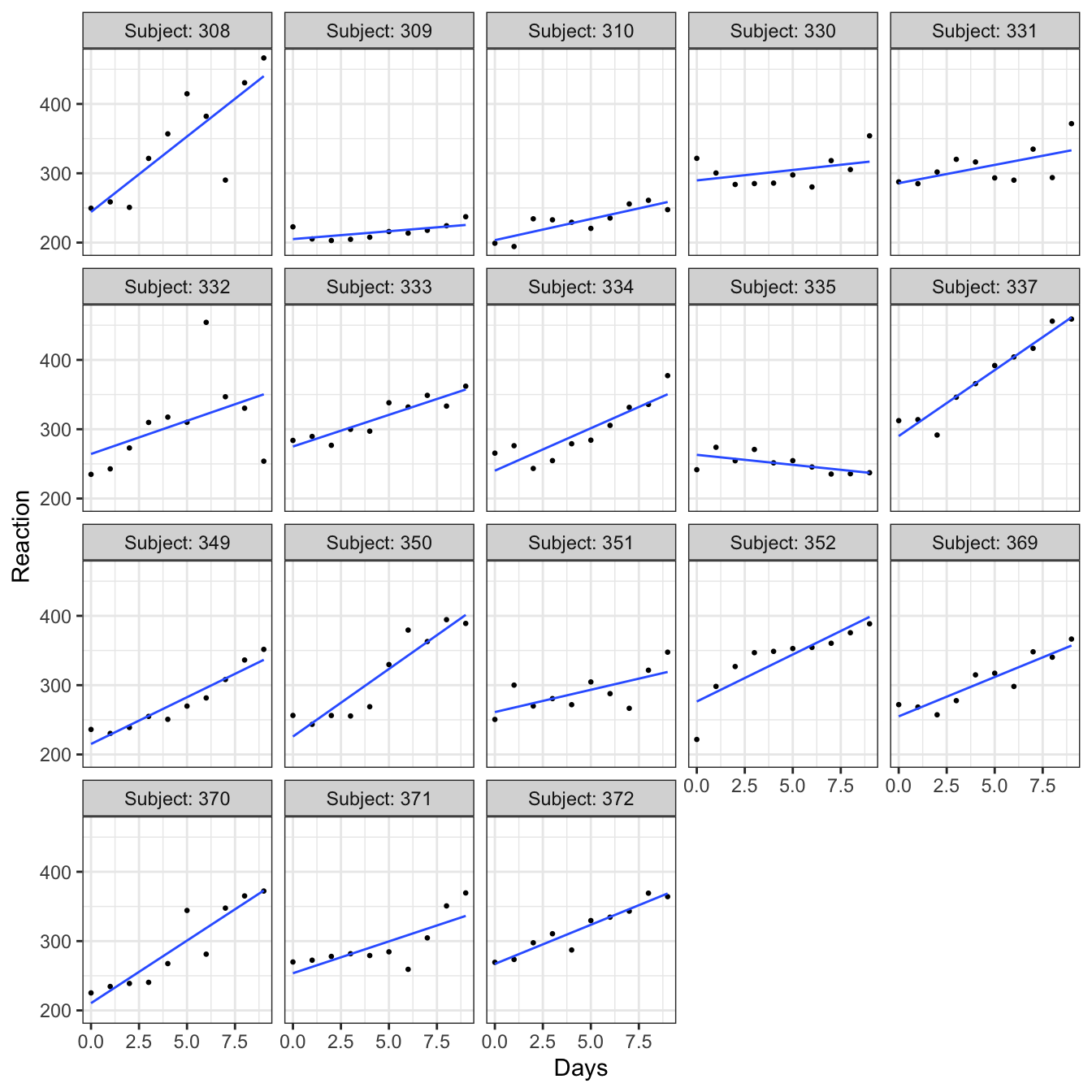
8.4.1 개체들의 선형 회귀모형
각 운전자 \(i\) 에 대하여 10일간 측정한 반응속도 \(y_{ij}\)를 시간에 대하여 선형모형으로 적합하면 개인별 회귀직선을 다음과 같이 표시할 수 있다.
\[ y_{ij} = \beta_{0i} + \beta_{1i} t_j + e_{ij},\quad i=1,2,\dots,18,\quad j=1,2,\dots,10 \tag{8.10}\]
여기서 오차항 \(e_{ij}\)은 서로 독립이며 \(N(0, \sigma^2_e)\)를 따른다고 가정한다.
행렬식으로는 다음과 같이 나타낼 수 있다.
\[ \pmb y_i =\pmb X_i \pmb \beta_{i} +\pmb e_i \]
여기서 \[ \pmb y_i=\begin{bmatrix} y_{i1} \\ y_{i2} \\ \vdots \\ y_{i,10} \end{bmatrix},~ \pmb X_i = \begin{bmatrix} 1 & 0 \\ 1 & 1 \\ \vdots & \vdots \\ 1 & 9 \end{bmatrix}, \pmb \beta_i= \begin{bmatrix} \beta_{0i} \\ \beta_{1i} \\ \end{bmatrix}, \pmb e_i= \begin{bmatrix} e_{i1} \\ e_{i2} \\ \vdots \\ e_{i,10} \end{bmatrix} \]
위의 식에서 \(\beta_{0i}\)와 \(\beta_{1i}\)는 \(i\)번째 운전사의 반응속도를 설명내는 회귀직선의 절편과 기울기이다. 절편 \(\beta_{0i}\)는 실험 시작때 반응속도를 의미하고 기울기 \(\beta_{1i}\)는 실험이 진행되는 동안 반응속도가 어떻게 변하는 지 변화의 방향과 크기를 보여준다. 함수 를 아래와 같이 이용하면 식 8.10 을 각 운전사마다 적합시켜 각각의 절편과 기울기를 구할 수 있다.
lmf1 <- lmList(Reaction ~ Days | Subject, sleepstudy)
lmf1Call: lmList(formula = Reaction ~ Days | Subject, data = sleepstudy)
Coefficients:
(Intercept) Days
308 244.1927 21.764702
309 205.0549 2.261785
310 203.4842 6.114899
330 289.6851 3.008073
331 285.7390 5.266019
332 264.2516 9.566768
333 275.0191 9.142045
334 240.1629 12.253141
335 263.0347 -2.881034
337 290.1041 19.025974
349 215.1118 13.493933
350 225.8346 19.504017
351 261.1470 6.433498
352 276.3721 13.566549
369 254.9681 11.348109
370 210.4491 18.056151
371 253.6360 9.188445
372 267.0448 11.298073
Degrees of freedom: 180 total; 144 residual
Residual standard error: 25.59182cor(coef(lmf1)) (Intercept) Days
(Intercept) 1.0000000 -0.1375534
Days -0.1375534 1.0000000plot(coef(lmf1), main = "intercepts and slopes on drivers: sleep study ")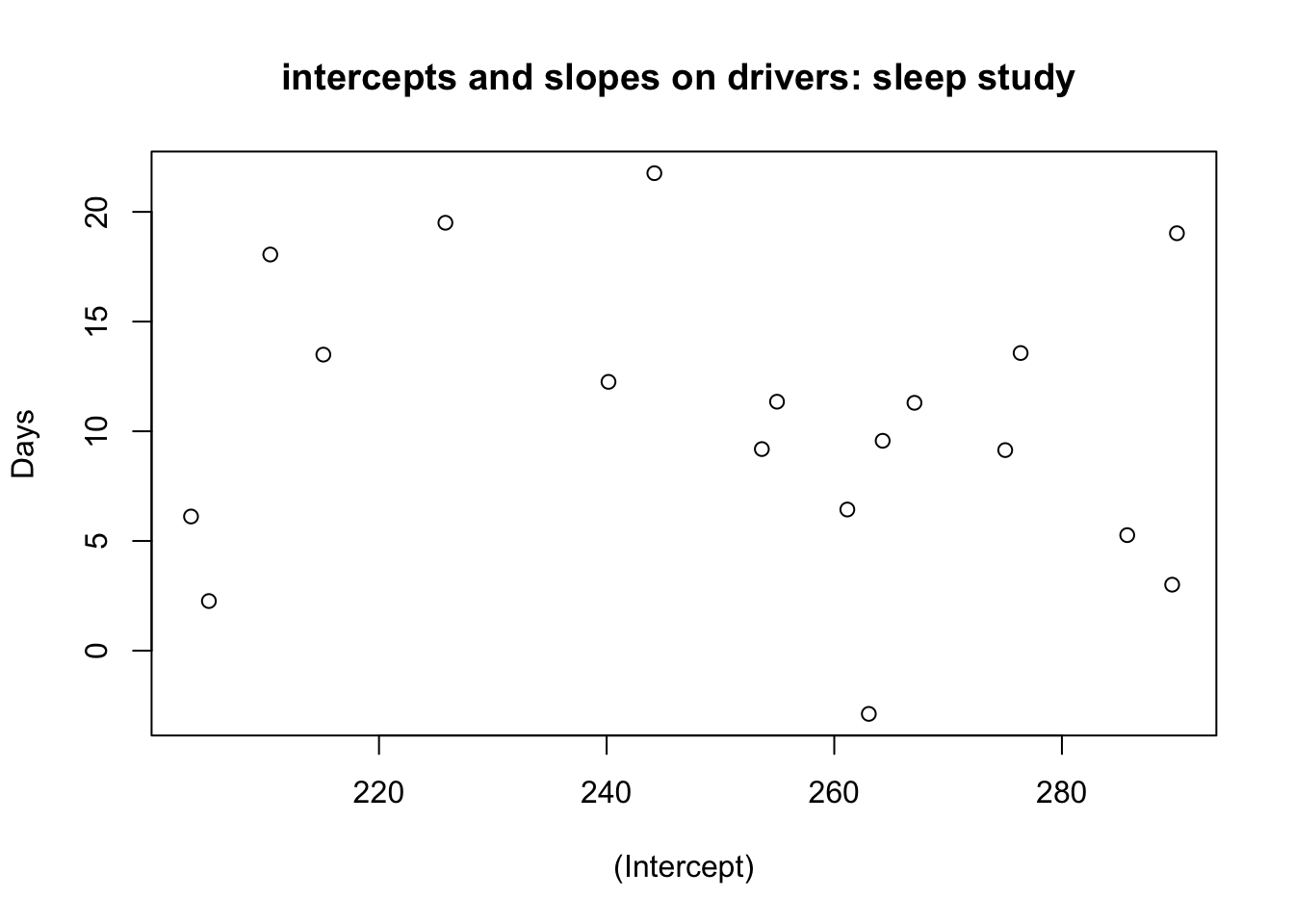
18개의 절편과 기울기는 큰 상관관계는 없는것으로 보이지만 약한 음의 상관계수가 나타났다.
절편과 기울기에 대한 분포를 보기 위하여 상자그림을 그려보면 평균을 중심으로 대칭인 분포를 보이고 있다.
boxplot(coef(lmf1)[1])
boxplot(coef(lmf1)[2])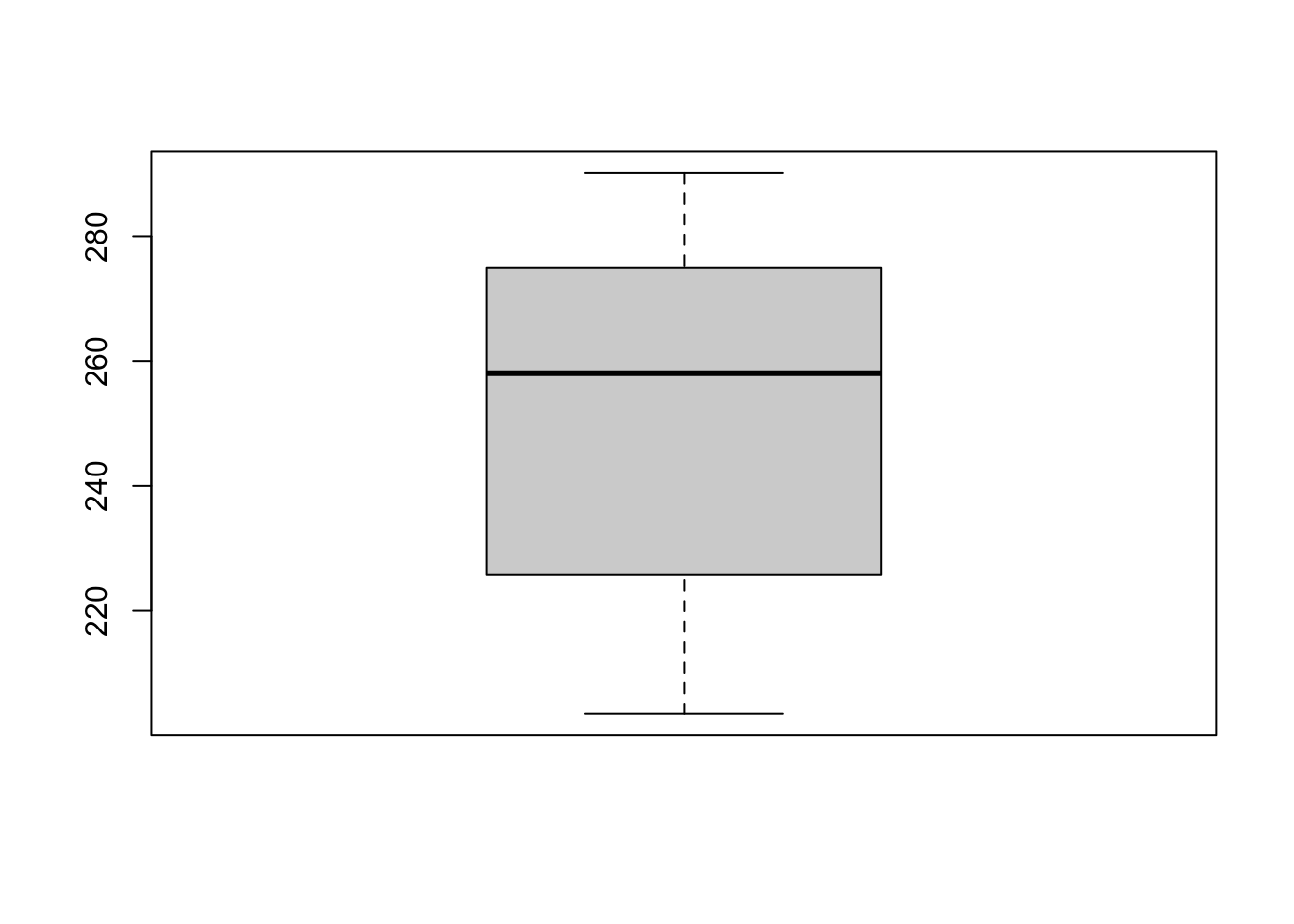
이제 각 운전사에 대하여 회귀식을 따로 적합하지 않고 전체 운전사들의 자료를 모두 합쳐서 하나의 회귀식을 고려할 수 있다. 개체의 특성을 반영하는 모형이 아닌 전체 집단에 대한 평균적인 모형(population model)을 고려하는 것이다.
\[ y_{ij} = \beta_0 + \beta_1 t_j + e_{ij} ,\quad i=1,2\dots,18, j=1,2, \dots, 10 \tag{8.11}\]
여기서 오차항은 서로 독립이며 \(N(0, \sigma^2_e)\)를 따른다고 가정한다.
위와 같은 전체 운전사 집단의 관측값을 운전자의 특성을 고려하지 않고 세운 모형으로서 시간에 따른 반응시간에 대한 모집단의 전체적인 평균적 함수 관계를 파악하는 모형이라고 할 수 있다.
lmpop <- lm(Reaction ~ Days, sleepstudy)
summary(lmpop)
Call:
lm(formula = Reaction ~ Days, data = sleepstudy)
Residuals:
Min 1Q Median 3Q Max
-110.848 -27.483 1.546 26.142 139.953
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 251.405 6.610 38.033 < 2e-16 ***
Days 10.467 1.238 8.454 9.89e-15 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 47.71 on 178 degrees of freedom
Multiple R-squared: 0.2865, Adjusted R-squared: 0.2825
F-statistic: 71.46 on 1 and 178 DF, p-value: 9.894e-15with(sleepstudy, plot(Days, Reaction, main = "Population and individual regression lines"))
abline(a = coef(lmpop)[1], b = coef(lmpop)[2], lwd = 3)
for (i in 1:18) {
xx <- as.numeric(coef(lmf1)[i, ])
abline(a = xx[1], b = xx[2], lty = 2)
}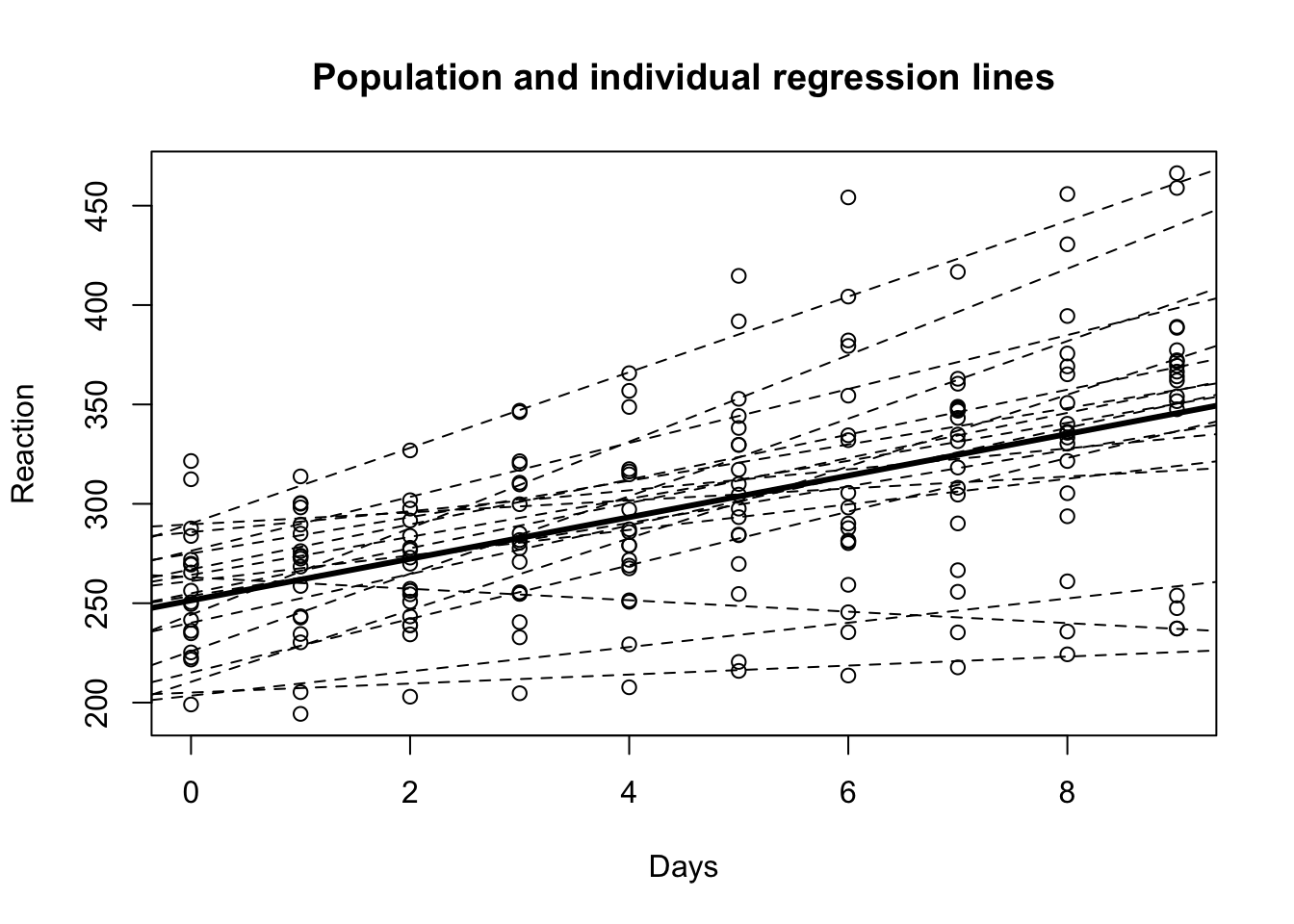
이제 각 운전사에 대하여 개체별로 적합한 회귀식의 계수들\((\hat \beta_{0i}, \hat \beta_{1i})\) 와 전체집단에 적한한 회귀식의 계수 \((\hat \beta_{0}, \hat \beta_{1})\)의 관계를 보면 개체별로 회귀 계수들의 평균이 전체에 적용한 모형의 계수와 매우 가까운 사실을 알 수 있다.
apply(coef(lmf1), 2, mean)(Intercept) Days
251.40510 10.46729 coef(lmpop)(Intercept) Days
251.40510 10.46729 8.4.2 임의계수 모형
앞 절의 모형과 분석에서 알 수 있듯이 한 개체에 대하여 여러 개의 관측값을 측정한 자료에 회귀방정식을 각각 적합시켜보고 또한 개체의 특성을 고려하지않은 전체 모형을 적합해보면 다음과 같은 두 가지 결과를 볼 수 있다.
- 각 개체별 회귀식은 개인의 특성을 반영한다. 즉, 개체에 따라 시간에 따른 반응시간의 변화가 다르게 나타난다.
- 하지만 개인별로 볼 때도 전체적으로는 시간에 따라서 반응시간이 증가하는 경향이 있음을 알 수 있다.
- 전체 자료에 적합한 모형을 보면 개인별로 적합한 모형의 공통적인 성격, 즉 시간에 따른 반응시간의 증가를 알 수 있다.
- 이러한 결과를 보고 각 개인의 변화는 전체적인 변화를 따르면서 각 개인의 특성이 반영되었다고 가정할 수 있다.
위에서 논의하였듯이 전체적인 경향과 개인의 특성을 동시에 고려할 수 있는 모형이 생각할 수 있고 이러한 모형이 다음과 같은 모형이다.
\[ y_{ij} = (\beta_0 + b_{0i}) + (\beta_1 + b_{1i}) t_j + e_{ij} , \quad i=1,2,\dots,18,\quad j=1,2,\dots,10 \tag{8.12}\]
모형 8.12 는 절편과 기울기가 두 개의 구성 요소로 더해져서 표현된다.기울기는 \(\beta_1+b_{1i}\)로서 나타내어지며 \(\beta_1\)은 모집단이 가지는 공통적인 경향을 반영하는 모수이고 \(b_{1i}\)는 \(i\) 번째 개체의 특성을 반영한 확률변수이다. 절편도 유사한 형식으로 구성된다.
각 개인에 대한 특성을 나타내는 변수 \((b_{0i}, b_{1i})\) 을 확률변수로 설정하고 이를 모수(\(\beta_0, \beta_1)\) (parameter or fixed effect)와 구별하여 임의효과(random effect)라고 한다.
임의효과는 모집단을 구성하는 개인이 표본에 추출되었다고 생각하며 확률분포를 따른다고 가정한다. 반복측정자료에서 인의효과를 공통으로 가지고 있는 관측치는 독립이 아니게 돼며 따라서 같은 개체에서 나온 관측값은 독립이 아니다.
모형 8.12 처럼 각 개인의 임의 효과가 포함된 선형모형을 임의계수모형(random coefficient model) 이라고 한다. 이러한 모형은 반복측정자료에서 개인의 특성을 고려하여 모형을 설정하는데 유용하다.
18명에 대한 회귀직선의 절편과 기울기를 보면 개인의 차이에 따른 변동을 볼 수 있으며 이러한 각 개인간의 변동을 임의효과 를 이용하여 다음과 같은 모형을 생각해보자.
\[ \pmb \beta_i= \begin{bmatrix} \beta_{0} \\ \beta_{1} \\ \end{bmatrix} +\begin{bmatrix} b_{0i} \\ b_{1i} \\ \end{bmatrix} , \quad \pmb b_i = \begin{bmatrix} b_{0i} \\ b_{1i} \\ \end{bmatrix} \sim N \left ( \begin{bmatrix} 0 \\ 0 \\ \end{bmatrix} , \begin{bmatrix} \sigma^2_{b1} & \rho \sigma_{b1} \sigma_{b2}\\ \rho \sigma_{b1} \sigma_{b2} & \sigma^2_{b2} \\ \end{bmatrix} \right ) \]
위의 모형은 각 개인의 회귀직선에서 각 절편과 기울기가 전체평균 \(\beta_0\)와 \(\beta_1\)를 따르며 각 개인의 차이는 전체평균에 임의효과인 \(b_{0i}\)와 \(b_{1i}\)가 더해져서 나타난다는 것을 의미한다. 이변량 임의효과 \(b_{0i}\)와 \(b_{1i}\)는 이변량 정규분포를 따르며 각각의 분산과 상관계수가 \(\sigma^2_{b1}\), \(\sigma^2_{b2}\), \(\rho\)이다.
다른 개체에 대한 임의효과는 서로 독립이며 임의 효과와 오차항은 독립이다. 여기서 오차항은 서로 독립이며 \(N(0, \sigma^2_e)\)를 따른다고 가정한다.
\[ Cov(\pmb b_{i}, \pmb b_{j}) =\pmb 0 \text{ when } i \ne j,\quad Cov(\pmb b_{i}, e_{jk}) =\pmb 0 \text{ for all } i,j,k \]
위 8.12 같은 혼합효과모형(mixed effects model)을 각 개인 \(i\)에 대하여 행렬식으로 표시하면 다음과 같다. 아래 모형식은 일반적으로 독립군집 모형에서 하나의 군집에 대한 반복된 관측값들에 대한 모형이며 독립군집 모형의 일반적인 이론은 부록 B 에서 더 논의할 것이다.
\[ \pmb y_i = \pmb X_i \pmb \beta + \pmb Z_i \pmb b_i + \pmb e_i , \quad i=1,2,\dots,18 \]
여기서
\[ \pmb y_i=\begin{bmatrix} y_{i1} \\ y_{i2} \\ \vdots \\ y_{i,10} \end{bmatrix},~\pmb X_i = \begin{bmatrix} 1 & 0 \\ 1 & 1 \\ \vdots & \vdots \\ 1 & 9 \end{bmatrix}, \pmb \beta= \begin{bmatrix} \beta_{0} \\ \beta_{1} \\ \end{bmatrix}, ~\pmb Z_i = \begin{bmatrix} 1 & 0 \\ 1 & 1 \\ \vdots & \vdots \\ 1 & 9 \end{bmatrix},~ \pmb b_i = \begin{bmatrix} b_{0i} \\ b_{1i} \\ \end{bmatrix},~ \pmb e_i= \begin{bmatrix} e_{i1} \\ e_{i2} \\ \vdots \\ e_{i,10} \end{bmatrix} \]
위의 각 개인에 대한 모형을 모두 합쳐서 하나의 혼합효과모형으로 나타내면 다음과 같이 표현할 수 있다.
\[ \pmb y = \pmb X \pmb \beta + \pmb Z \pmb b + \pmb e \tag{8.13}\]
여기서 반응변수벡터 \(\pmb y\)와 고정효과 \(\pmb \beta\)에 대한 계획행렬 \(X\)는 각 개인의 반응변수벡터 \(\pmb y_i\)와 \(\pmb X_i\)를 행으로 쌓아놓은 것으로 표현된다. 오차항에 대한 벡터 \(\pmb e\)도 동일한 형식의 벡터이다.
\[ \pmb y=\begin{bmatrix} \pmb y_{1} \\ \pmb y_{2} \\ \vdots \\ \pmb y_{18} \end{bmatrix},~\pmb X = \begin{bmatrix} \pmb X_1 \\ \pmb X_2 \\ \vdots \\ \pmb X_{18} \end{bmatrix} ~ \pmb e = \begin{bmatrix} \pmb e_1 \\ \pmb e_2 \\ \vdots \\ \pmb e_{18} \end{bmatrix} \]
임의효과 벡터 \({\pmb b}\) 는 각 개인에 대한 임의효과벡터 \(\pmb b_i\) 를 행으로 쌓아놓은것과 같고 임의효과에 대한 계획행렬 \(\pmb Z\) 는 각 개인의 계획행렬 \(\pmb Z_i\) 를 대각원소로 구성하는 행렬이다.
\[ \pmb b=\begin{bmatrix} \pmb b_{1} \\ \pmb b_{2} \\ \vdots \\ \pmb b_{18} \end{bmatrix},~\pmb Z = \begin{bmatrix} \pmb Z_1 & 0 & \dots & 0 \\ 0 & \pmb Z_2 & \dots & 0 \\ \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & \dots & \pmb Z_{18} \end{bmatrix} \]
혼합모형 8.13 를 lmer() 함수를 이용하여 적합시켜보자. 모형에서 (1 + Days|Subject) 이 개체에 대하여 절편과 기울기에 대한 임의효과를 지정한다.
fm1 <- lmer(Reaction ~ 1 + Days + (1 + Days|Subject), sleepstudy)
summary(fm1)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: Reaction ~ 1 + Days + (1 + Days | Subject)
Data: sleepstudy
REML criterion at convergence: 1743.6
Scaled residuals:
Min 1Q Median 3Q Max
-3.9536 -0.4634 0.0231 0.4634 5.1793
Random effects:
Groups Name Variance Std.Dev. Corr
Subject (Intercept) 612.10 24.741
Days 35.07 5.922 0.07
Residual 654.94 25.592
Number of obs: 180, groups: Subject, 18
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 251.405 6.825 17.000 36.838 < 2e-16 ***
Days 10.467 1.546 17.000 6.771 3.26e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
Days -0.138위의 혼합모형 적합결과를 살펴보자. 첫째로 고정효과에 대한 추정식은 다음과 같다
fixef(fm1)(Intercept) Days
251.40510 10.46729 또한 오차항에 대한 분산 및 임의효과의 분산성분과 상관계수는 다음과 같이 나타난다.
VarCorr(fm1) Groups Name Std.Dev. Corr
Subject (Intercept) 24.7407
Days 5.9221 0.066
Residual 25.5918 위의 고정효과와 임의효과의 분산성분에 대한 추정치를 이용하여 모형의 적합의 결과를 다음과 같이 나타낼 수 있다.
\[ \text{Reaction Time} = N(251.405 + 10.467 \text{ Days}, 25.6^2) \]
\[ \begin{bmatrix} b_{0i} \\ b_{1i} \\ \end{bmatrix} \sim N \left ( \begin{bmatrix} 0 \\ 0 \\ \end{bmatrix} , \begin{bmatrix} 24.74^2 & (0.07)(24.74)(5.92)\\ (0.07)(24.74)(5.92)& 5.92^2 \\ \end{bmatrix} \right ) \]
이제 임의효과 \(\pmb b\)에 대한 예측(prediction)을 생각해보자. 우리는 오직 관측벡터 \(\pmb y\)만을 관측하고 임의효과 \(\pmb b\)는 관측을 할 수 없는 확률변수이다. 하지만 주어진 관측벡터와 추정된 분산으로 임의효과의 값을 예측할 수있으며 그 결과는 다음과 같다.
re <- ranef(fm1)$Subject
re (Intercept) Days
308 2.2585509 9.1989758
309 -40.3987381 -8.6196806
310 -38.9604090 -5.4488565
330 23.6906196 -4.8143503
331 22.2603126 -3.0699116
332 9.0395679 -0.2721770
333 16.8405086 -0.2236361
334 -7.2326151 1.0745816
335 -0.3336684 -10.7521652
337 34.8904868 8.6282652
349 -25.2102286 1.1734322
350 -13.0700342 6.6142178
351 4.5778642 -3.0152621
352 20.8636782 3.5360011
369 3.2754656 0.8722149
370 -25.6129993 4.8224850
371 0.8070461 -0.9881562
372 12.3145921 1.2840221plot(re, main ="prediction of random effects ")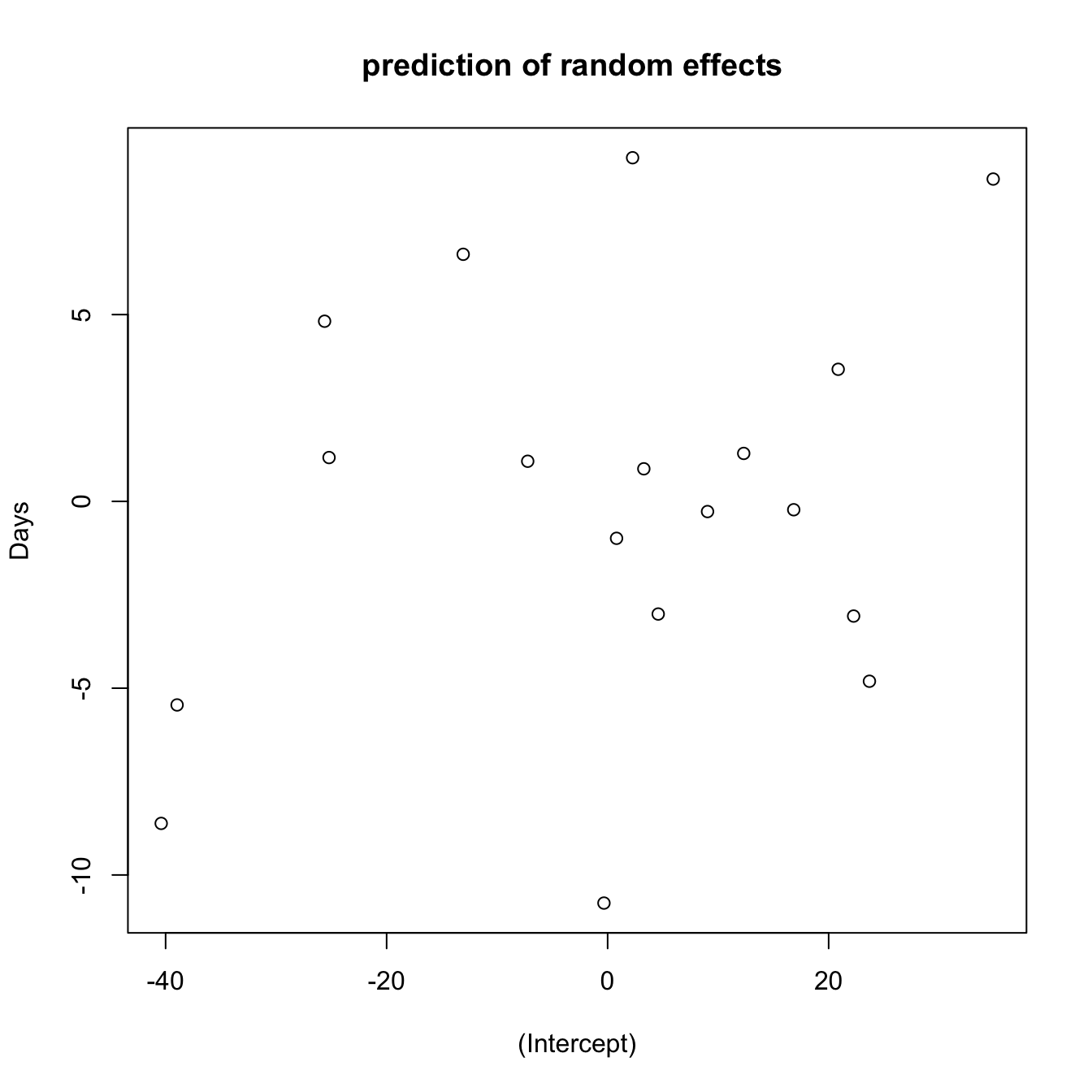
예측된 각 개인의 절편과 기울기에 대한 임의효과 \(b_{0i}\)과 \(b_{1i}\)에 고정효과의 추정량 \(\hat \beta\)를 더해주면 각 개인의 절편과 기울기에 대한 예측값을 구할 수 있다.
beta <- matrix(as.numeric(fixef(fm1)),18,2,byrow=T)
beta + re (Intercept) Days
308 253.6637 19.6662617
309 211.0064 1.8476053
310 212.4447 5.0184295
330 275.0957 5.6529356
331 273.6654 7.3973743
332 260.4447 10.1951090
333 268.2456 10.2436499
334 244.1725 11.5418676
335 251.0714 -0.2848792
337 286.2956 19.0955511
349 226.1949 11.6407181
350 238.3351 17.0815038
351 255.9830 7.4520239
352 272.2688 14.0032871
369 254.6806 11.3395008
370 225.7921 15.2897709
371 252.2122 9.4791297
372 263.7197 11.7513080위의 결과를 각 개체에 대해 별도의 회귀직선을 적합시켜서 얻은 18개의 절편과 기울기와 비교해보자.
coef(lmf1) (Intercept) Days
308 244.1927 21.764702
309 205.0549 2.261785
310 203.4842 6.114899
330 289.6851 3.008073
331 285.7390 5.266019
332 264.2516 9.566768
333 275.0191 9.142045
334 240.1629 12.253141
335 263.0347 -2.881034
337 290.1041 19.025974
349 215.1118 13.493933
350 225.8346 19.504017
351 261.1470 6.433498
352 276.3721 13.566549
369 254.9681 11.348109
370 210.4491 18.056151
371 253.6360 9.188445
372 267.0448 11.298073이렇게 혼합모형을 통해서 얻은 각 개인의 절편과 기울기에 대한 예측값과 각각의 개인에 대해서 회귀직선을 따로 적합하여 얻은 절편과 기울기의 관계를 그림으로 그려보면 다음과 같다. 즉 혼합모형을 통해서 얻은 각 개인의 절편과 기울기는 절편과 기울기의 전체평균값 방향으로 축소되는 경향(shrinkage)을 볼수있다.
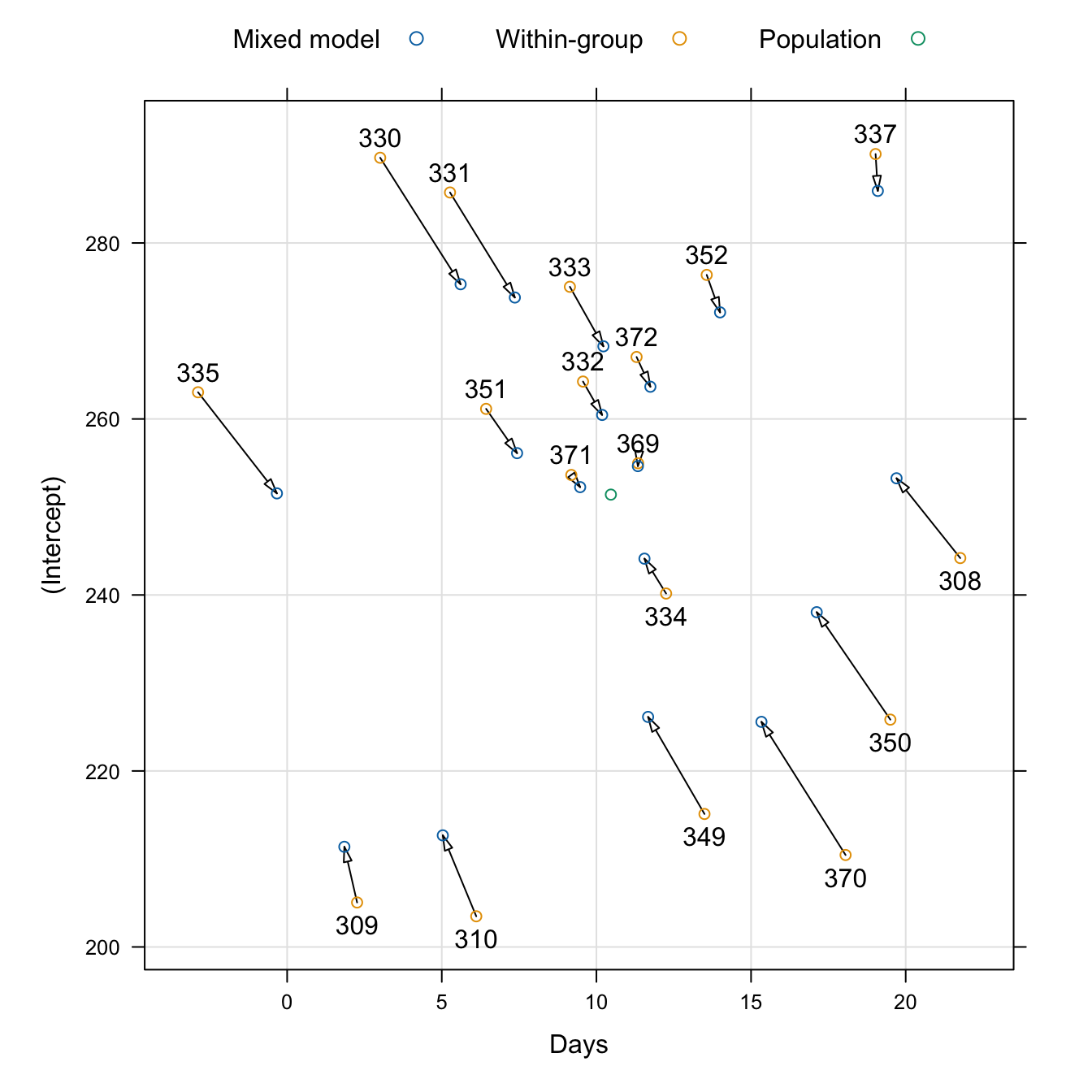
여기서 혼합모형의 식 8.13 의 임의효과에 대한 계획행렬 \(Z\)의 구조를 살펴보자. R 의 적합된 결과에서 getME 함수를 이용하여 계획행렬 \(\pmb Z\)의 전치행렬(transpose matrix, \(\pmb Z^t\))을 얻을 수 있다. 계획행렬 \(\pmb Z\)는 그 값의 많은 부분이 0으로 구성되어 있어서 성김행렬(saprse matrix)라고 부르며 이런 행렬은 특별한 형식으로 저장되어 있다.
image(getME(fm1,"Zt"))
또한 혼합모형의 식 8.13 에서 임의효과의 상관계수가 \(\rho=0\)인 경우의 모형을 고려해 보자
\[ \begin{bmatrix} b_{0i} \\ b_{1i} \\ \end{bmatrix} \sim N \left ( \begin{bmatrix} 0 \\ 0 \\ \end{bmatrix} , \begin{bmatrix} \sigma^2_{b1} & 0\\ 0 & \sigma^2_{b2} \\ \end{bmatrix} \right ) \]
임의효과의 상관계수가 \(\rho=0\)인 모형은 아래와 같이 (1+Days | Subject) 를 사용하는 대신 두 개의 바 || 를 사용한 (1+Days || Subject)으로 적합시키면 결과를 다음과 같이 얻을 수 있다.
fm2 <- lmer(Reaction ~ 1 + Days + (1+Days||Subject), sleepstudy)
# 다음 명령어는 위의 명령어와 같은 모형을 적합한다.
# fm2 <- lmer(Reaction ~ 1 + Days + (1|Subject) + (0+Days|Subject), sleepstudy)
summary(fm2)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: Reaction ~ 1 + Days + (1 + Days || Subject)
Data: sleepstudy
REML criterion at convergence: 1743.7
Scaled residuals:
Min 1Q Median 3Q Max
-3.9626 -0.4625 0.0204 0.4653 5.1860
Random effects:
Groups Name Variance Std.Dev.
Subject (Intercept) 627.57 25.051
Subject.1 Days 35.86 5.988
Residual 653.58 25.565
Number of obs: 180, groups: Subject, 18
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 251.405 6.885 18.156 36.513 < 2e-16 ***
Days 10.467 1.560 18.156 6.712 2.59e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
Days -0.184위의 고정효과와 임의효과의 분산성분에 대한 추정치를 이용하여 모형의 적합의 결과를 다음과 같이 나타낼 수 있다.
\[ \text{Reaction Time} = N(251.405 + 10.467 \text{ Days}, 25.6^2) \]
\[ \begin{bmatrix} b_{0i} \\ b_{1i} \\ \end{bmatrix} \sim N \left ( \begin{bmatrix} 0 \\ 0 \\ \end{bmatrix} , \begin{bmatrix} 25.1^2 & 0\\ 0& 6.0^2 \\ \end{bmatrix} \right ) \]
두 모형, 즉 절편과 기울기에 대한 두 임의효과가 종속인지 또는 독립인지에 대한 두 모형을 AIC(Akaike Information Criteris)로 비교하해 보자. 두 모형은 AIC의 값은 거의 동일하지만 임의효과의 상관게수가 0인 모형이 AIC 값이 약간 작으며 상관게수의 추정치가 메우 작으므로 임의효과의 상관게수가 0인 모형을 선택하는 것이 합리적이라고 판단된다.
AIC(fm1)[1] 1755.628AIC(fm2)[1] 1753.6698.5 예제: 고혈압 강하제 살험
여기서 다룰 예제는 Jaewon Lee (2005) 6장에 나오는 예제이다.
고혈압 환자 66명을 대상으로 32명에게는 기존의 혈압 강하제(C)를 투여하고, 나머지 34명에게는 새로운 혈압 강하제(E)를 투여하였다. 환자가 치료를 시작하기 전에 혈압을 측정하고(0주) 치료를 받은 후 4주, 8주 후에 2번 반복 측정하였다. 이 실험의 목표는 다음과 같다.
- 기존의 약과 새로운 혈압 강하제 간의 유의한 차이가 있는가?
- 방문 시간(
time)에 따라서 혈압(bp)의 차이가 있는가? - 약(
trt)과 방문 시간(time) 간에 상호작용(interaction)이 있는가?
이제 자료를 읽어서 blood_data에 저장하자.
blood_data<- read.csv(here("data", "ex0601.txt"), header=T, sep="")
head(blood_data,5) id trt time bp
1 1 C 0 95
2 2 C 0 100
3 3 C 0 98
4 4 C 0 114
5 5 C 0 110모형식을 고려하기 전에 각 처리 그룹에서 시간에 따른 혈압의 변화를 살펴보자. 강하제를 복용한 후에 평균 혈압은 크게 내려갔지만 8주 후에는 다소 올라가는 경향을 보인다.
with(blood_data, interaction.plot(x.factor = time, trace.factor = trt, response = bp))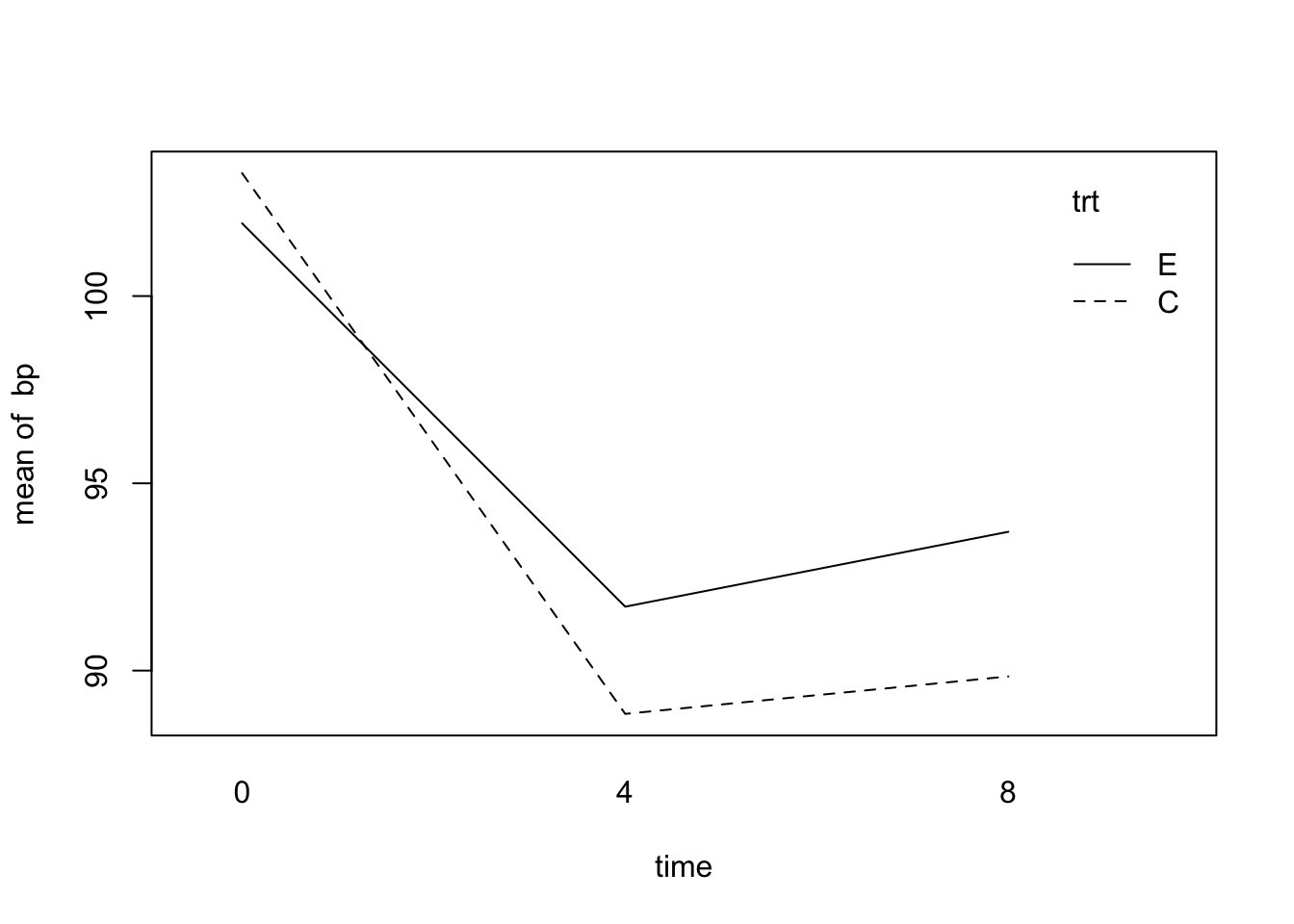
8.5.1 혼합효과 모형
반응값 \(y_{ijk}\)를 \(i\) 번째 강하제(\(i=1,2\))를 복용한 \(j\) 번째 환자의 \(k\) 시간에 측정한 혈압이라고 하자(\(j=1,2,..,n_i\), \(k=0,1,2\)).
먼저 약을 복용하기 전의 혈압 \(y_{ij0}\) 은 처리 전의 기준이 되는 값이다. 따라서 우리는 4주와 8주에 측정한 혈압, \(y_{ij1}\)와 \(y_{ij2}\) 에서 0주에 측정한 혈압 \(y_{ij0}\)을 뺀 두 개의 차이, \(d_{ij1}\) 과 \(d_{ij2}\)를 반응 변수로 사용할 것이다. 각 환자는 2개의 관측값을 가지며 이는 반복측정 자료이다.
\[ d_{ij1} = y_{ij1} -y_{ij0}, \quad d_{ij2} = y_{ij2} -y_{ij0} \]
혈압의 차이를 계산하여 다음과 같이 새로운 데이터프레임을 만들자.
df0 <- blood_data %>% filter(time == 0) %>% select(id, bp) %>% rename( bp0 = bp)
df1 <- blood_data %>% filter(time != 0)
blood_data1 <- left_join(df1, df0, by='id') %>% mutate(d = bp - bp0)
head(blood_data1 ,10) id trt time bp bp0 d
1 1 C 4 88 95 -7
2 2 C 4 95 100 -5
3 3 C 4 90 98 -8
4 4 C 4 98 114 -16
5 5 C 4 81 110 -29
6 6 C 4 98 100 -2
7 7 C 4 92 100 -8
8 8 C 4 79 100 -21
9 9 C 4 81 107 -26
10 10 C 4 85 101 -16with(blood_data1, interaction.plot(x.factor = time, trace.factor = trt, response = d))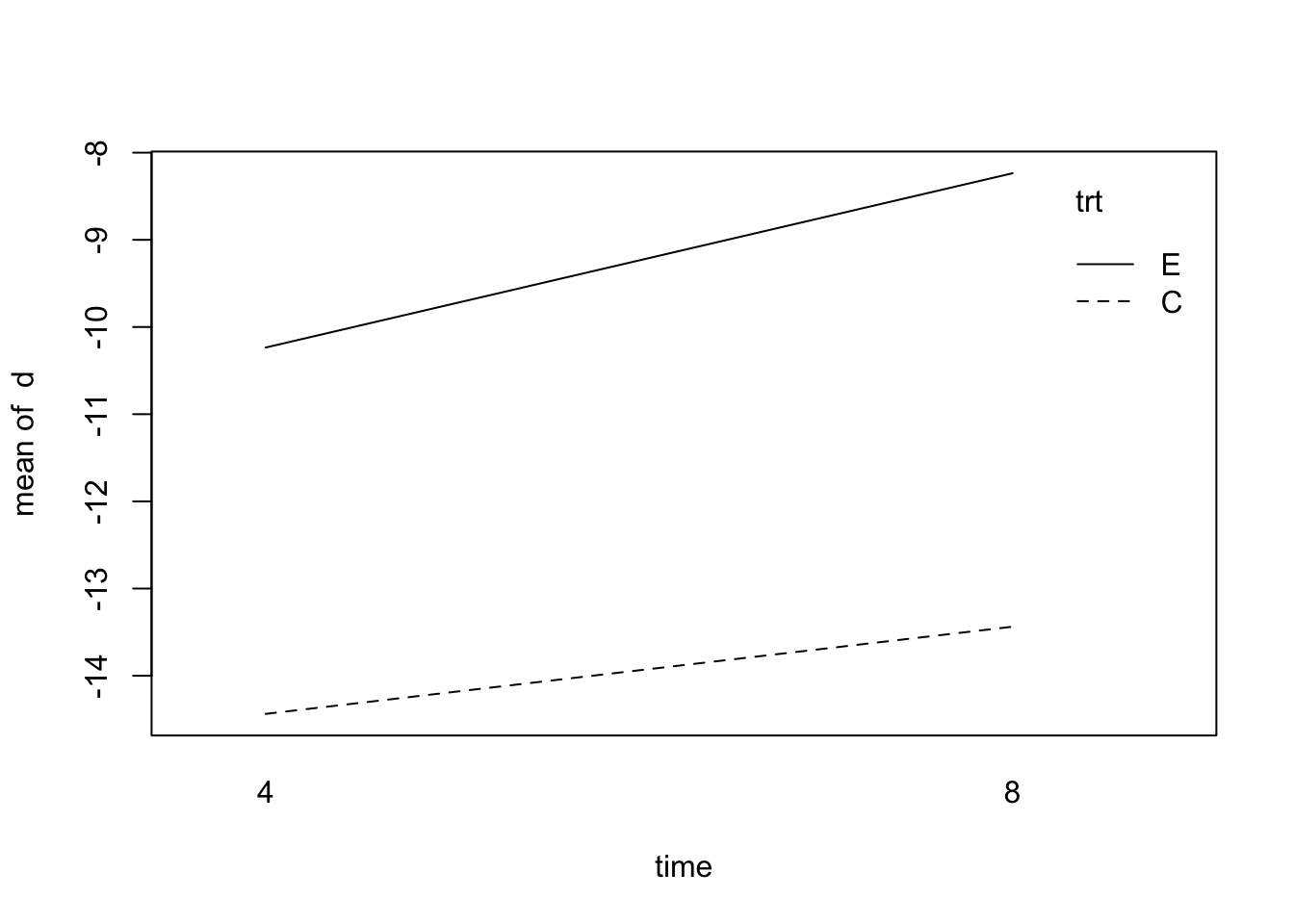
이제 다음과 같은 모형을 고려하자.
\[ d_{ijk} = \mu + \alpha_i + \beta_k + (\alpha\beta)_{ik} + b_{ij} + e_{ijk}, \quad i=1,2 ~~ j=1,...,n_i~~ k=1,2 \tag{8.14}\]
일단 반복 측정한 시점이 2번이므로 측정 시간은 연속형 변수가 아닌 범주형 변수로 지정한다.
. 위의 모형식 8.14 에서 각 항의 의미는 다음과 같다.
- \(\mu\) : 전체 평균 혈압
- \(\alpha_i\) : 혈압 강하제의 효과 (\(i=1,2\))
- \(\beta_k\) : 시간 효과(\(k=1,2\))
- \((\alpha\beta)_{ik}\) : 강하제와 시간의 상호작용
- \(b_{ij} \sim_{iid} N(0,\sigma_b^2)\) : 환자의 효과를 나타내는 임의효과 (\(i=1,2\), \(j=1,2,\dots,n_i\))
- \(e_{ijk} \sim_{iid} N(0, \sigma_e^2)\): 오차항
위에서 환자의 효과를 나타내는 임의효과와 오차항은 독립이라고 가정한다.
이제 자료에서 치료약(trt), 시간(time), 환자의 ID(id)를 범주형 변수로 변환하자.
blood_data1$id <- factor(blood_data1$id)
blood_data1$trt <- factor(blood_data1$trt)
blood_data1$time <- factor(blood_data1$time)이제 다음과 같은 R 명령문을 이용하여 모형 8.14 을 적합하고 추정 결과를 살펴 보자.
blood_fit <- lmer(d ~ trt + time + trt*time +(1|id), data=blood_data1)
summary(blood_fit)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: d ~ trt + time + trt * time + (1 | id)
Data: blood_data1
REML criterion at convergence: 862
Scaled residuals:
Min 1Q Median 3Q Max
-1.92294 -0.44315 0.05264 0.36653 2.14310
Random effects:
Groups Name Variance Std.Dev.
id (Intercept) 58.00 7.616
Residual 14.87 3.857
Number of obs: 132, groups: id, 66
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) -14.4375 1.5091 78.3627 -9.567 8.24e-15 ***
trtE 4.2022 2.1026 78.3627 1.999 0.0491 *
time8 1.0000 0.9642 64.0000 1.037 0.3036
trtE:time8 1.0000 1.3434 64.0000 0.744 0.4594
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) trtE time8
trtE -0.718
time8 -0.319 0.229
trtE:time8 0.229 -0.319 -0.718위의 적합 결과를 보면 다음과 같은 해석이 가능하다.
- 혈압 강하제 간의 유의한 차이는 있다. 기존의 혈압 강하제(C)가 더 효과적이다
- 시간에 따른 효과의 차이는 유의하지 않다.
- 강하제와 시간 간의 상호작용도 유의하지 않다.
또한 환자의 개인적인 효과를 반영한 임의효과의 분산이 오차항의 분산의 거의 4배이다.이는 개인 간의 변동이 개인 내의 변동보다 매우 크다는 것을 의미한다.
\[ \hat \sigma^2_b = 58.00 \quad \hat \sigma^2_e = 14.87\] 반복측정한 자료의 상관계수, 즉 그룹 내의 관측값의 상관계수는 0.7956 으로 매우 높다.
\[ \hat \rho(d_{ij1},d_{ij2}) = \frac{\hat \sigma^2_b }{\hat \sigma^2_b + \hat \sigma^2_2} =\frac{58.0}{58.0 + 14.9} = 0.7956 \]
이제 각 요인에 대한 유의성을 보기 위하여 분산분석을 실시해 보자. 선택 명령문으로 ddf = "Kenward-Roger"를 사용하는 것이 좋으며 이는 혼합효과 모형에서 잔차제곱합의 자유도를 적절하게 추정해 준다. 위의 분산분석 결과를 보면 약의 효과와 상호작용은 앞에서 내린 결론과 동일하지만 시간에 따른 효과가 유의하게 나타난다.
anova(blood_fit, ddf = "Kenward-Roger")Type III Analysis of Variance Table with Kenward-Roger's method
Sum Sq Mean Sq NumDF DenDF F value Pr(>F)
trt 82.855 82.855 1 64 5.5701 0.02133 *
time 74.182 74.182 1 64 4.9870 0.02904 *
trt:time 8.242 8.242 1 64 0.5541 0.45937
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 18.5.2 임의효과가 없는 모형
만약 반복측정 자료의 구조를 무시하고 개인에 대한 임의효과를 고려하지 않으면 어떻게 될까? 이러한 가정은 실험에서 얻은 모든 반응값들이 독립이라는 것이다.
다음과 같이 개인에 대한 임의효과가 없는 모형을 고려하고 적합해 보자.
\[ d_{ijk} = \mu + \alpha_i + \beta_k + (\alpha\beta)_{ik} + e_{ijk}, \quad i=1,2 ~~ j=1,...,n_i~~ k=1,2 \tag{8.15}\]
blood_fit1 <- lm(d ~ trt + time + trt*time , data=blood_data1)
summary(blood_fit1)
Call:
lm(formula = d ~ trt + time + trt * time, data = blood_data1)
Residuals:
Min 1Q Median 3Q Max
-17.765 -6.562 -1.562 6.286 23.235
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -14.438 1.509 -9.567 <2e-16 ***
trtE 4.202 2.103 1.999 0.0478 *
time8 1.000 2.134 0.469 0.6402
trtE:time8 1.000 2.974 0.336 0.7372
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.537 on 128 degrees of freedom
Multiple R-squared: 0.08017, Adjusted R-squared: 0.05861
F-statistic: 3.719 on 3 and 128 DF, p-value: 0.01323Anova(blood_fit1, type="III")Anova Table (Type III tests)
Response: d
Sum Sq Df F value Pr(>F)
(Intercept) 6670.1 1 91.5284 < 2e-16 ***
trt 291.1 1 3.9945 0.04777 *
time 16.0 1 0.2196 0.64018
trt:time 8.2 1 0.1131 0.73719
Residuals 9328.0 128
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1혈압 강하제의 효과가 임의효과를 포함한 모형과 같이 유의하게 나타난다. 그런데 여기서 임의효과를 포함 하지 않는 모형의 분석 결과에 유의해야 할 점은 다음과 같다.
임의효과를 고려하지 않으면 마치 66명의 두 배인 132 명으로 구성된 독립 표본으로 실험한 것처럼 가정하는 것이다. 따라서 표본의 수가 늘어나는 효과가 생긴다.
반면 임의 효과로 설명되는 그룹의 변동이 오차의 변동에 합쳐지기 때문에 오차항의 분산이 크게 추정된다.
위의 두 분석 결과를 비교해보면 혼합효과 모형에서 오차항의 분산에 대한 추정치는 \(\hat \sigma_e^2 =14.87\) 이지만 임의효과를 고려하지 않은 모형에서는 \(\hat \sigma_e^2 =(8.537)^2 = 72.88\) 로 추정된다.
하지만 임의효과를 고려하지 않은 모형에서는 표본의 수가 늘어나므로, 오차항의 분산이 크게 추정되더라도 추정량에 대한 표준오차(standard error)는 혼합모형과 유사하게 나타난다.
혼합모형으로 추정한 그룹 내 상관계수(\(\hat \rho =0.8\))가 매우 크게 나타났으므로 관측값들이 모두 독립이라는 가정은 적절하지 않다.
각 환자에 대하여 두 반응값을 연결하여 그리면 환자들의 두 반응값들이 매우 가깝게 나타나는 것을 알 수 있다.
ggplot(blood_data1, aes(x=id, y=d, color=trt)) +
geom_point() +
geom_line() 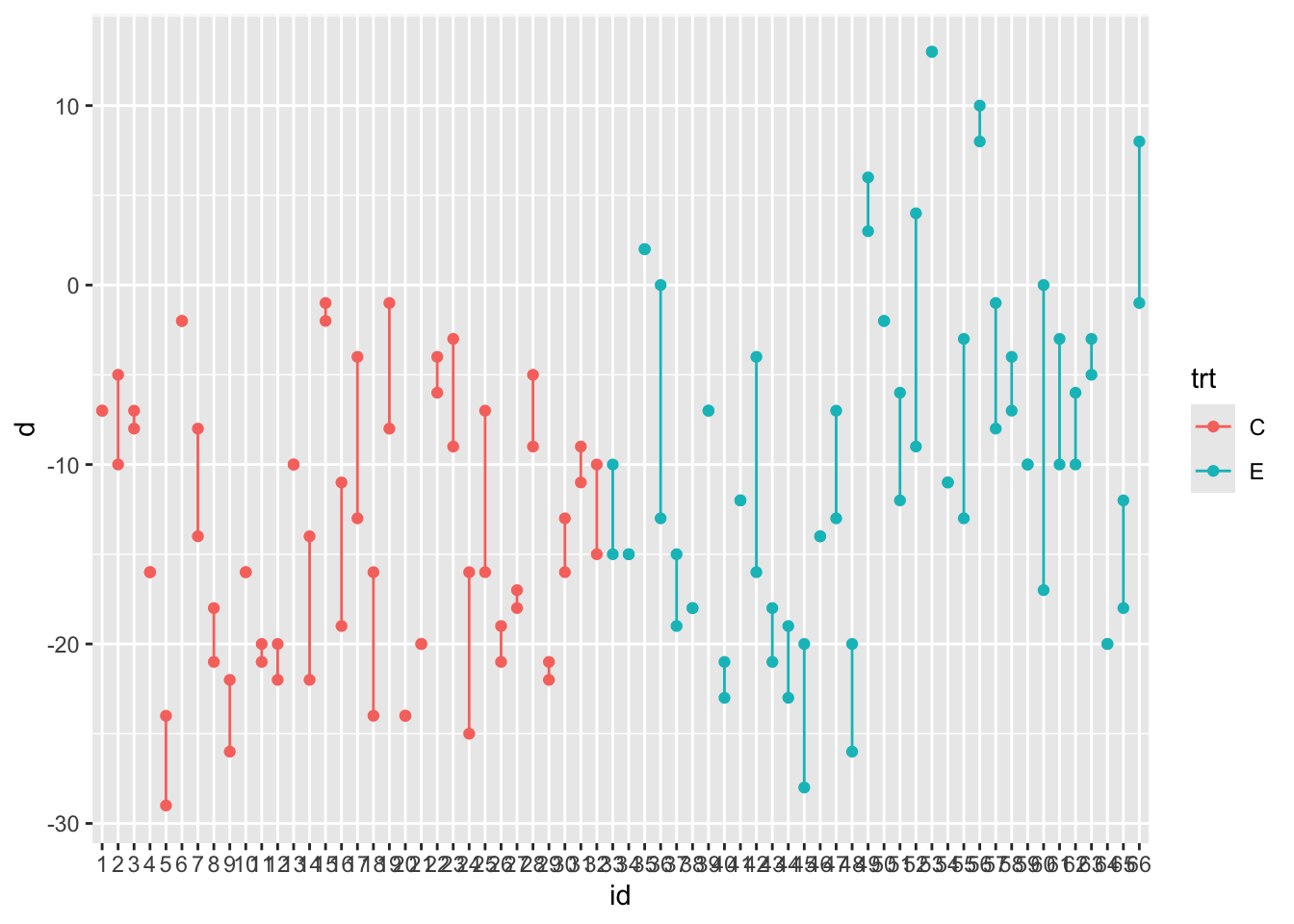
8.5.3 공분산분석
실제로 많은 임상 실험에서는 여러 번 반복 측정을 실시해도 결과를 분석하는 경우 최종 측정값만을 고려한다. 이제 약을 복용하기 전과 8주의 혈압의 차이를 반응변수로 하는 공분산 분석을 실시해 보자.
약을 복용하기 전과 8주의 혈압의 차이 \(d_{ij2} = y_{ij2} - y_{ij0}\) 를 반응변수로 하고 공변량을 실험 전 혈압 \(y_{ij0}\)으로 하여 분석을 실시한다. 모형은 공분산분석 모형으로 다음과 같다.
\[ d_{ij2} = \mu + \alpha_i + \beta y_{ij0} + e_{ij} \]
blood_data2 <- blood_data1 %>% filter(time == 8)
head(blood_data2,5) id trt time bp bp0 d
1 1 C 8 88 95 -7
2 2 C 8 90 100 -10
3 3 C 8 91 98 -7
4 4 C 8 98 114 -16
5 5 C 8 86 110 -24plot(d ~ trt, data=blood_data2)
이제 공분산 모형을 적합해 보자. 처리 간의 차이도 매우 유의하고 실험 전의 혈압도 유의하다. 주목할 점은 실험 전의 혈압에 대한 회귀계수의 부호가 음수이므로 약을 먹기 전에 혈압이 높을수록 약을 먹은 후의 혈압이 더 많이 감소한다. 이러한 현상은 임상실험에서 자주 나타나는 현상이다. 일반적으로 질병의 정도가 심한 환자일 수록 평균적으로 치료 효과가 더 커진다.
blood_ancova <- lm( d ~ trt + bp0, data = blood_data2)
summary(blood_ancova)
Call:
lm(formula = d ~ trt + bp0, data = blood_data2)
Residuals:
Min 1Q Median 3Q Max
-13.982 -6.485 -0.014 5.300 23.505
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 32.8989 21.3060 1.544 0.1276
trtE 4.6010 1.9778 2.326 0.0232 *
bp0 -0.4486 0.2058 -2.180 0.0330 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.952 on 63 degrees of freedom
Multiple R-squared: 0.1578, Adjusted R-squared: 0.1311
F-statistic: 5.903 on 2 and 63 DF, p-value: 0.004469Anova(blood_ancova, type="III")Anova Table (Type III tests)
Response: d
Sum Sq Df F value Pr(>F)
(Intercept) 150.8 1 2.3843 0.12757
trt 342.2 1 5.4115 0.02323 *
bp0 300.4 1 4.7505 0.03304 *
Residuals 3983.6 63
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1