임상실험에서 요인은 치료 방법(treatmanet)이며 보통의 경우 2개의 수준를 가진다. 두 개의 수준 중 하나는 실험자가 연구대상으로 고려한 효과가 기대되는 치료/약품(active)이며 다른 하나의 수준은 제어 수준(control)이다. 임상실험에서는 대부분의 경우 효과가 있는 치료나 약품을 적용하지 않아도 위약효과(placebo effect)가 나타나기 때문에 실험자가 사용하려고 하는 치료법의 효과는 언제나 제어군에서 나타난 효과와의 차이로 파악해야 한다.
병렬 계획은 환자가 임의로 선택된 하나의 치료/약품만 받는 실험을 말한다. 참고로 뒤에서 살펴보겠지만 환자가 2개 이상의 치료을 받는 교차실험(crossover design)도 있다.
8.1.1 공분산 분석의 개요
많은 임상 실험에서는 실험의 질과 수준이 실제 환자를 치료하는 환경과 동일하게 유지하는 것을 원칙으로 한다. 따라서 임상실험은 동장이나 연구실에서 수행하는 매우 정교하게 통제된 실험과 다르게 치료방법 외의 다양한 요인들이 영향을 미치게 된다. 이러한 다양한 요인들은 맹검화(blinding) 등 다양한 실험 기법을 사용하여 통제된다.
다양한 요인의 영향을 통제하려는 시도에도 불구하고 대표적으로 실험의 결과에 영향을 미치는 요인은 환자의 초기 상태(baseline)과 기관/병원(center/hospital effect)이다. 임상실험에 참가하는 환자들은 약품을 처리받기 전의 상태가 모두 다르기 때문에 처리의 효과뿐만이 아니라 환자의 초기 상태도 최종 반응값에 영향을 미친다. 또한 대부분의 임상실험은 여러 개의 병원(또는 지역, 나라)에서 동시에 실행되므로 병원, 지역, 국가의 특성에 따라서 임상시험의 결과에 영향을 미친다.
이렇게 실험에서 주요하게 고려하는 요인인 아닌 다른 요인이 영향을 미친다고 판단될 때 그 요인을 공변량 (covariate) 라고 부르며 공변량을 모형에 포함시키는 분석을 공분산분석(Analysis of Covariance; ANCOVA)라고 부른다.
공변량의 형태는 보통 실험 단위가 가지고 있는 특성이나 실험자가 가진 특성을 반영한다. 예를 들어 다음과 같은 공변량의 형태가 있다.
교육 방법을 비교하는 실험에서 학생들이 가진 학습 역량
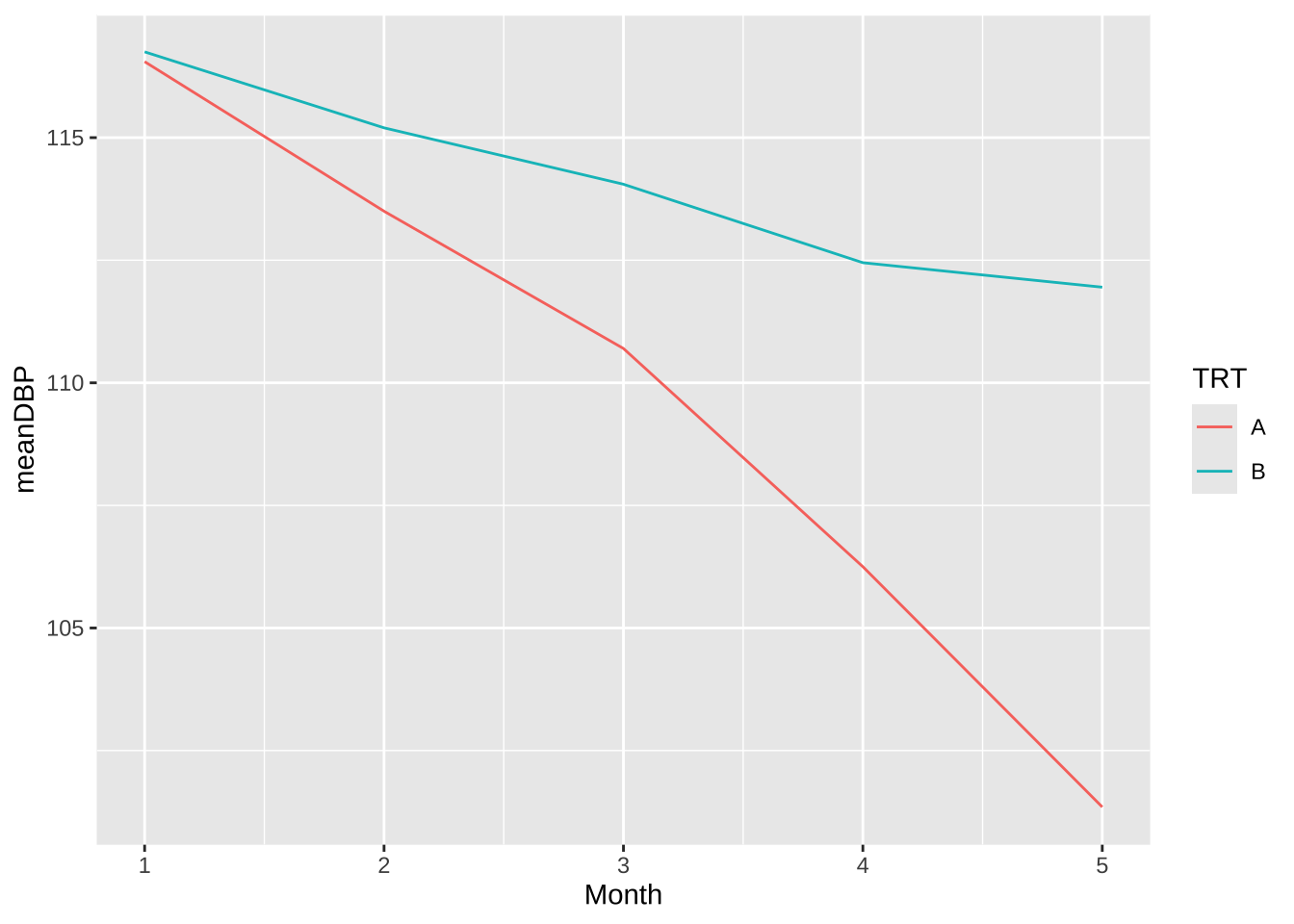
혈압 강하를 위한 약품에 대한 실험에서 임상 참가 전 환자의 혈압과 나이
천식에 대한 약품 실험이 여러 국가에서 실행될때 국가의 효과
암을 진단하는 방법에 대한 임상 실험이 다수의 병원에서 진행될 때 병원의 효과
일반적으로 임상실험이나 관측연구에서는 관심이 있는 처리(treatment)나 요인(factor)뿐만 아니라 다른 요인들도 반응변수에 영향을 미친다. 이러한 다른 요인들의 영향을 제거하기 위한 방법은 여러가지가 있지만 실험인 경우 임의화 방법(randomization)으로 그 영향을 상쇄시킬 수 도 있고 관측연구인 경우에는 사례-대조연구 방법을 이용하여 그 영향을 최소화하려고 노력을 한다. 하지만 다양한 통제 방법에도 불구하고 여러 가지 변수들이 반응변수에 영향을 미친다. 이러한 경우에 중요한 요인을 모형에 포함시켜서 그 영향을 반영하고 동시에 자료의 변동을 부가적으로 설명해주는 방법이 공분산 분석이다.
8.1.2 공분산분석의 모형
실험에서 공변량은 연속형 변수일 수도 있고 범주형일 수 도 있다. 만약 공변량이 범주형 변수인 경우 분석의 방법은 이원배치 분산분석과 매우 유사하다. 이 절에서는 공변량은 연속형 변수라고 가정하고 분석 방법을 논의할 것이다. 또한 공변량이 2개 이상인 경우도 있지만 이 절에서는 공변량이 하나인 경우만 고려한다.
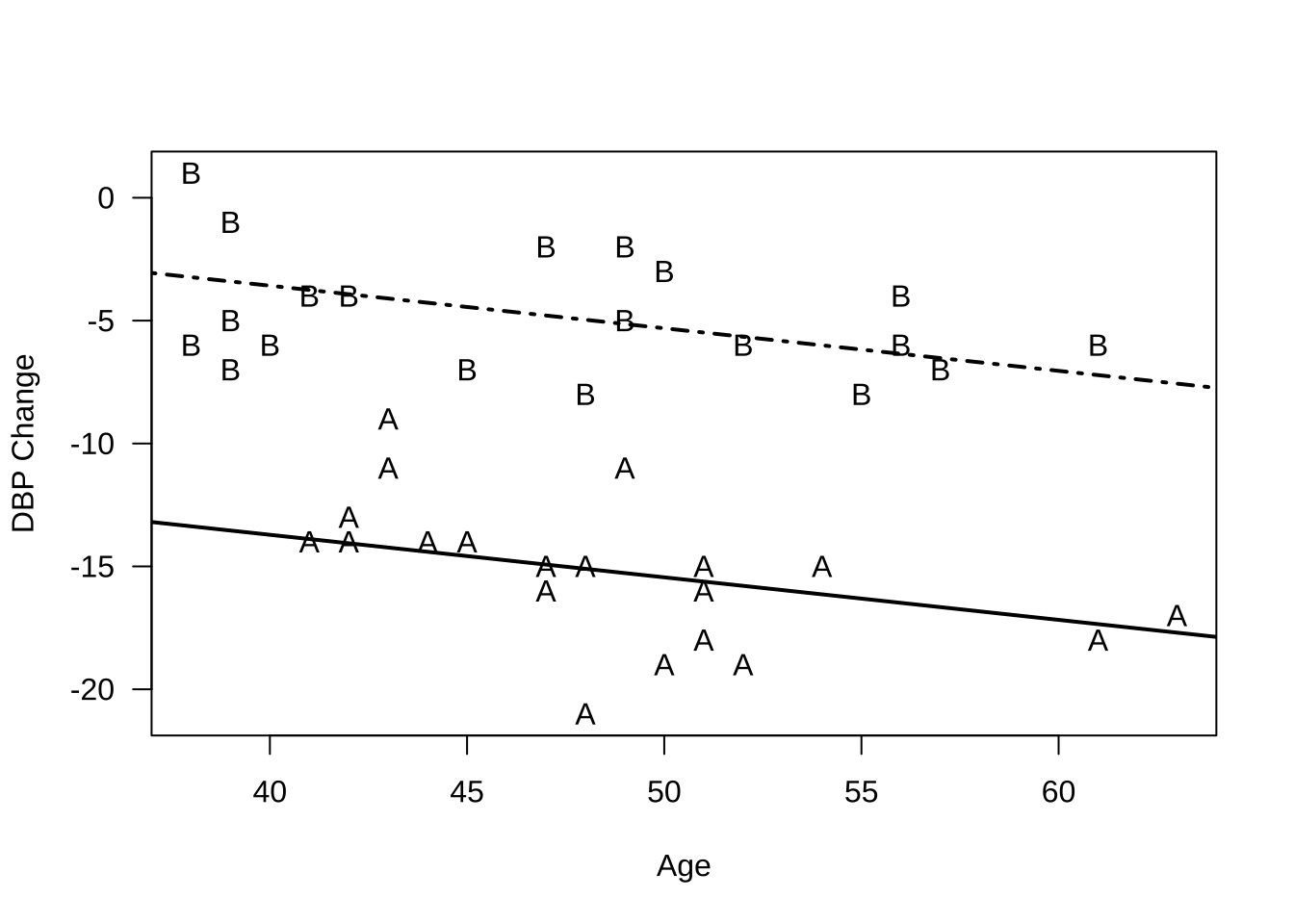
공분산분석의 모형은 일원배치 분산분석 모형(처리의 수는 \(a\)개, 반복수는 \(r\))에 공변량 \(x\)의 효과를 다음과 같이 더해주는 것이다.
모형 식 8.1 에서 \(x_{ij}\)는 관측값 \(y_{ij}\)의 공변량이며 이를 중심화(centering)하여 회귀모형의 독립변수로 표현한다. 모형 식 8.1 에서 \(\bar x_{..} = sum_i sum_j x_{ij}/(ar)\) 로 공변량 값의 전체 평균이다.
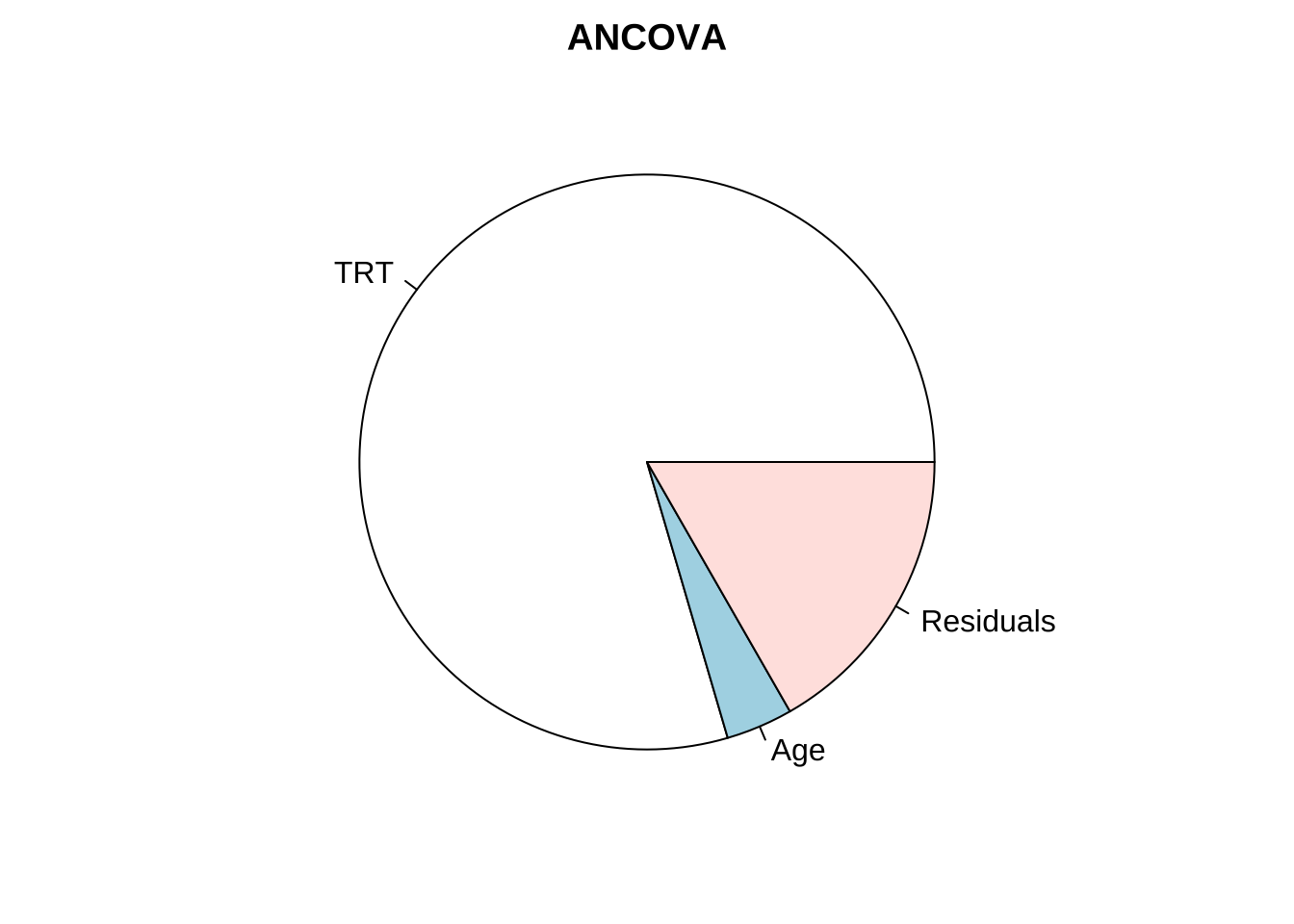
Analysis of Variance Table
Response: diff
Df Sum Sq Mean Sq F value Pr(>F)
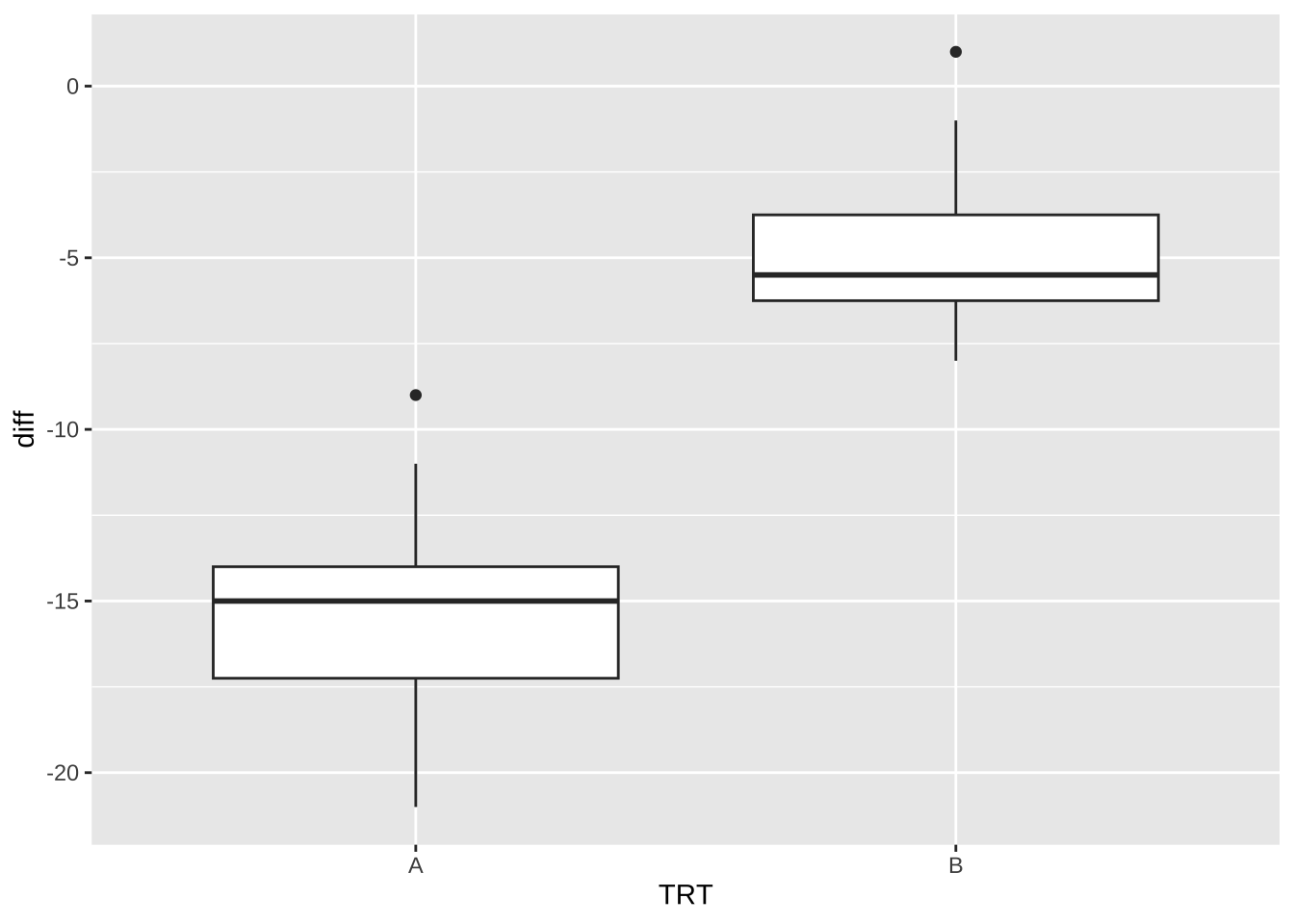
TRT 1 1081.60 1081.60 176.0395 1.228e-15 ***
Age 1 51.07 51.07 8.3119 0.006525 **
Residuals 37 227.33 6.14
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
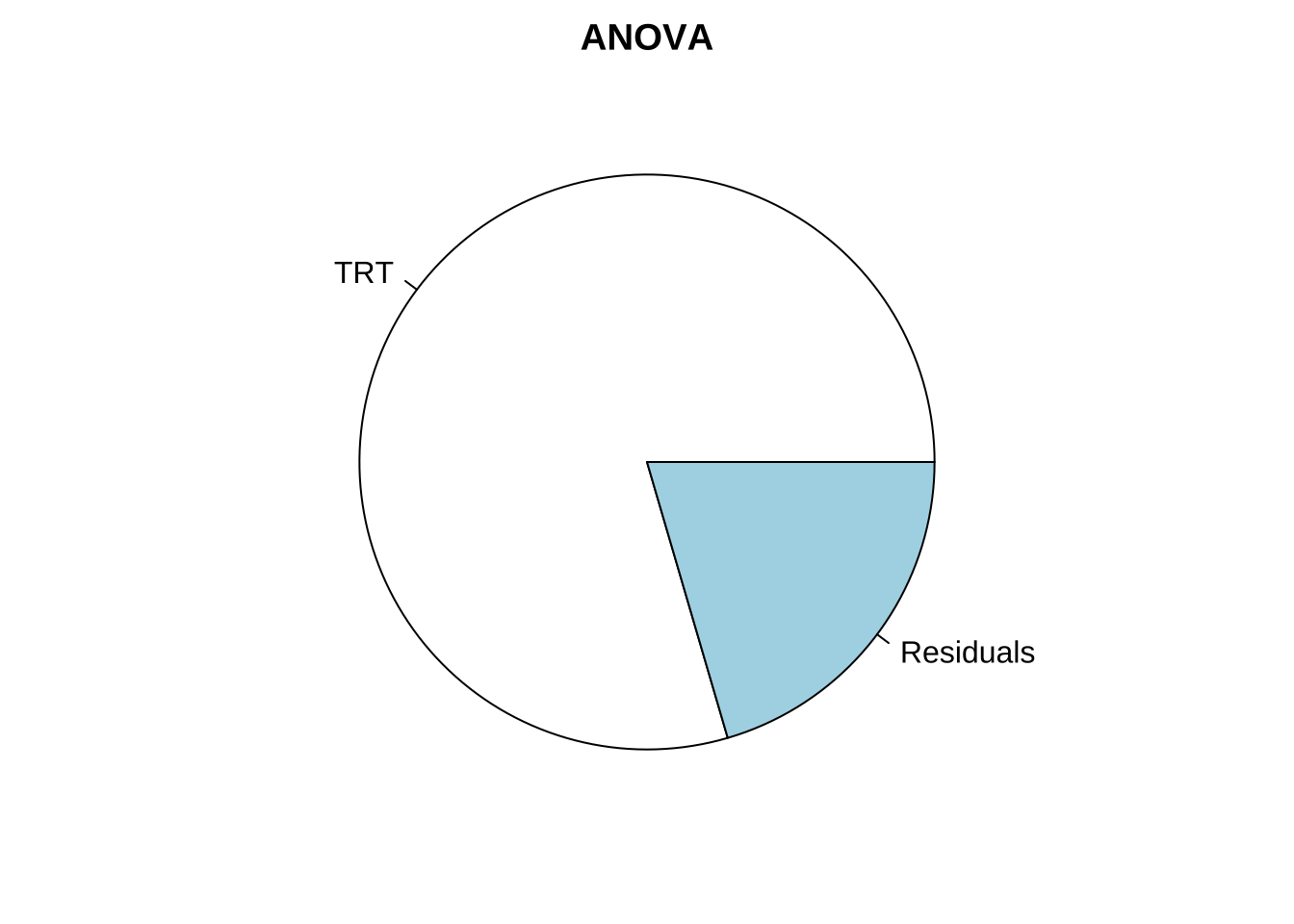
공변량이 있는 경우 분산분석표에서 다음과 같이 제곱합의 분해가 얻어진다.
\[
SS_T = SS_A + SS_X + SS'_E
\tag{8.4}\]
이제 공변량이 없는 경우의 제곱합의 분해 식 8.3 과 있는 경우의 분해 식 8.3 을 보면 공변량이 없는 경우의 오차제곱합이 두 개의 제곱합으로 분해되는 것을 알 수 있다.
\[
SS_E = SS_X + SS'_E
\tag{8.5}\]
즉, 만약 반응변수와 공변량의 상관관계가 크면 공변량에 대한 제곱합 \(SS_X\)가 커질 것이며 이는 공변량이 있는 모형에서 처리 효과를 검정하는 경우 사용되는 오차제곱합 \(SS'_E\) 가 공변량이 없는 경우의 \(SS_E\) 보다 작아지는 것을 알 수 있다.
결론적으로 반응변수와 공변량의 상관관계가 크면, 공변량을 포함하는 모형에서 처리 효과를 검정하는 \(F\)-값이 공변량을 포함하지 않는 것보다 일반적으로 커지게 된다. 이는 공변량이 처리효과로 설명하지 못하는 변동 중의 일부를 설명하기 때문에 처리효과에 대한 검정력이 높아지게 된다.
\(100(1-2\alpha)\)% 신뢰구간을 이용하는 경우 검정의 Size 와 유의수준은 ? ( Kang (2008) 참조)
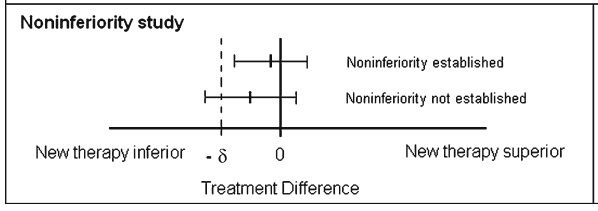
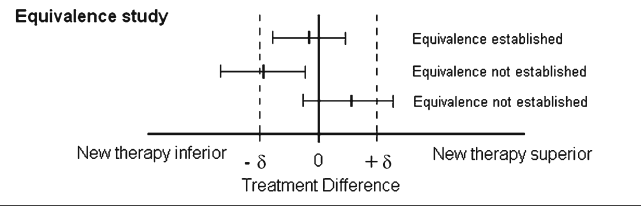
8.3 교차실험과 동등성 검정
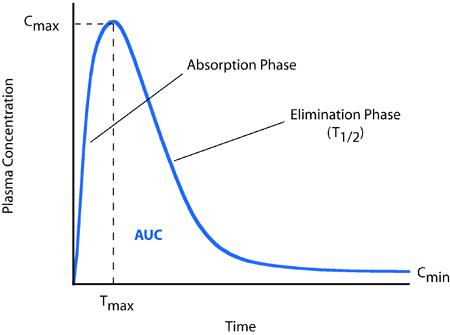
8.3.1 생체이용률(Bioavailability)
the rate and extent to which the active ingredient is absorbed from a drug product and becomes available at the site of action
주성분 또는 그 활성대사체가 제제로부터 전신순환혈로 흡수되는 속도와 양의 비율
Pharmacokinetic (PK) measures (평가항목) of bioavailability
\(AUC_t\): Area under the blood or plasma concentration-time curve; 일정시간까지 혈중농도-시간곡선하면적
\(C_{max}\): Maximum Concentration; 최고혈중농도
\(T_{max}\): Time to Maximum Concentration; 최고혈중농도 도달시간
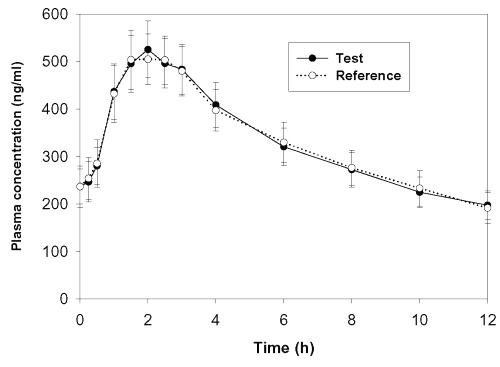
8.3.2 약품 주성분의 생체이용률의 평균적 변화
8.3.3 생물학적동등성의 정의: FDA 과 KFDA
Bioequivalence by FDA
absence of a significant difference in Bioavailability between two formulations…. when administered at the same molar dose under similar conditions in an appropriately designed study
in vivo: Bioequivalence
in vitro: Bioequivalence
KFDA
의약품동등성시험이란 그 주성분 ·함량 및 제형이 동일한 두 제제에 대한 의약품동등성을 입증하기 위해 실시하는 생물학적동등성시험, 비교용출시험, 비교붕해등 기타시험의 생체내·외 시험을 말한다.
8.3.4 생물학적동등성 실험의 설계
생체이용률(bioavailibility)은 개인간에 변동이 크다
개인효과(individual effect)를 제거하기 위한 쌍비교 t-검정 (paired t-test)의 개념을 도입
실험자가 두 개의 처리를 모두 받는다.
생동성실험은 주로 교차시험(crossover design)을 이용한다.
제재의 반감기가 긴 경우 등 특수한 경우는 병렬계획(Parallel design) 실험도 가능하다.
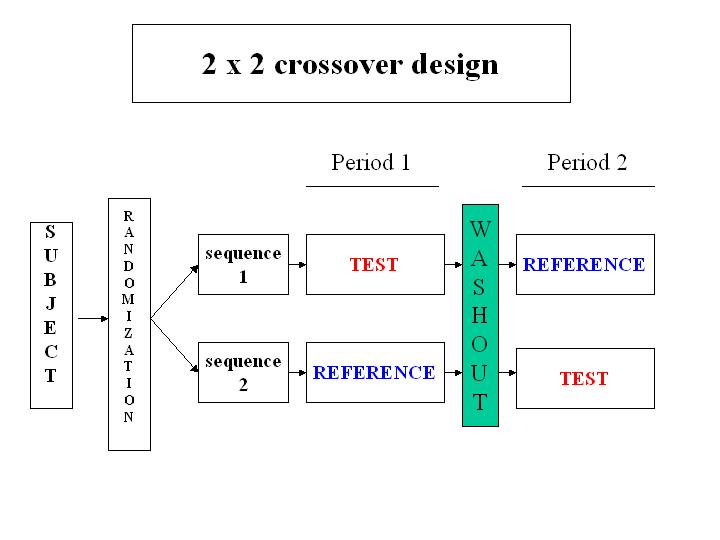
2x2 교차실험
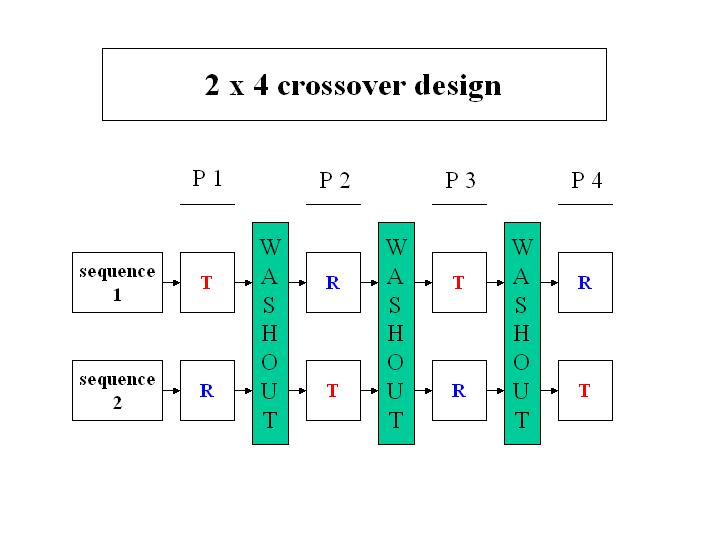
2x4 교차시험
8.3.5 교차실험에 대한 통계적 모형
보통 10-20명의 실험 대상자
각 실험 대상자가 2개(3개 또는 4개)의 반응값(PK responses)을 가진다.
각 실험대상자의 반응값은 독립이 아니다 (correlated response; repeated measurements)
실험대상자 간의 변이가 크다 (large between-subject variation)
시험약과 대조약간의 (로그)반응값의 평균의 차이가 주 검토대상이다.
정규분포를 가정한 선형혼합모형(linear mixed model)
8.3.6 평균적 생물학적동등성에 대한 가설
The absence of a significant difference (중대한 차이가 없다) in two population means between two formulations .