예를 들어 블럭 1 (\(L_1=0, L_2=0\)) 에 베치된 처리에 대하여 선형식의 값을 구해보자.
블럭
처리
\(L_1 (ACD)\)
\(L_2 (BCD)\)
1
\((0)\)
\(\texttt{MOD} (0+0+0, 2) = 0\)
\(\texttt{MOD} (0+0+0, 2) = 0\)
1
\(ABC\)
\(\texttt{MOD} (1+1+0, 2) = 0\)
\(\texttt{MOD} (1+1+0, 2) = 0\)
1
\(ABD\)
\(\texttt{MOD} (1+0+1, 2) = 0\)
\(\texttt{MOD} (1+0+1, 2) = 0\)
1
\(CD\)
\(\texttt{MOD} (0+1+1, 2) = 0\)
\(\texttt{MOD} (0+1+1, 2) = 0\)
예를 들어 블럭 2 (\(L_1=0, L_2=1\)) 에 베치된 처리에 대하여 선형식의 값을 구해보자.
블럭
처리
\(L_1 (ACD)\)
\(L_2 (BCD)\)
2
\(AC\)
\(\texttt{MOD} (1+1+0, 2) = 0\)
\(\texttt{MOD} (0+1+0, 2) = 1\)
2
\(AD\)
\(\texttt{MOD} (1+0+1, 2) = 0\)
\(\texttt{MOD} (0+0+1, 2) = 1\)
2
\(B\)
\(\texttt{MOD} (0+0+0, 2) = 0\)
\(\texttt{MOD} (1+0+0, 2) = 1\)
2
\(BCD\)
\(\texttt{MOD} (0+1+1, 2) = 0\)
\(\texttt{MOD} (1+1+1, 2) = 1\)
이렇게 모든 처리에 대하여 구한 선형식의 값은 다음과 같이 함수 conf.design() 로 구할 수 있다. 아래 주어진 블럭배치의 결과는 자료 df 에서 처리들이 블럭에 배치된 것과 일치함을 확인할 수 있다.
먼저 상호작용효과 \(ACD\) 와 \(BCD\) 가 블록과 교락되도록 정의할 수 있는 행렬을 만들어 보자. 아래 0 과 1 로 구성된 \(4 \times 2\) 행렬을 보면, 먼저 4개의 인자를 나타내는 4개의 열로 구성되어 있으며 각 행은 블록과 교락된 상호작용효과에 해당되는 요인을 1로 표시한 것이다. 따라서 첫 행은 \(ACD\) 에 해당되는 요인들을 1로 표시하고 나머지 행은 \(BCD\) 에 해당되는 요인들을 1로 표시한 것이다.
아래 함수 conf.design() 의 결과 df2 는 앞에서 만든 실험자료 df 와 처리와 블럭의배정이 일치하는 것을 확인할 수 있다.
6.1.3 결합요인
상호작용효과 \(ACD\) 와 \(BCD\) 가 블록과 교락되어 있을 경우 발생하는 결합요인은 \(AB\) 이다. 따라서 상호작용효과 \(AD\) 도 블록 효과와 교락된다.
\[ ACD \times BCD = ABC^2 D^2= AB \]
6.1.4 Yates 계산법
이제 자료 df 에 함수 yates() 를 다음과 같이 적용하여 각 효과의 추정치(effect)를 게산해 보자. 참고로 attr(a, "mean") 는 Yates 추정치가 저장된 a 에서 반응값의 전체 평균 \(\bar y_{....}\) 을 구하는 함수이다.
a <-yates(df$y, c("A", "B", "C", "D"))a
A B AB C AC BC ABC D AD BD
21.625 3.125 0.125 9.875 -18.125 2.375 1.875 14.625 16.625 -0.375
ABD CD ACD BCD ABCD
4.125 -1.125 -1.625 -2.625 1.375
attr(,"mean")
70.0625
attr(a, "mean")
70.0625
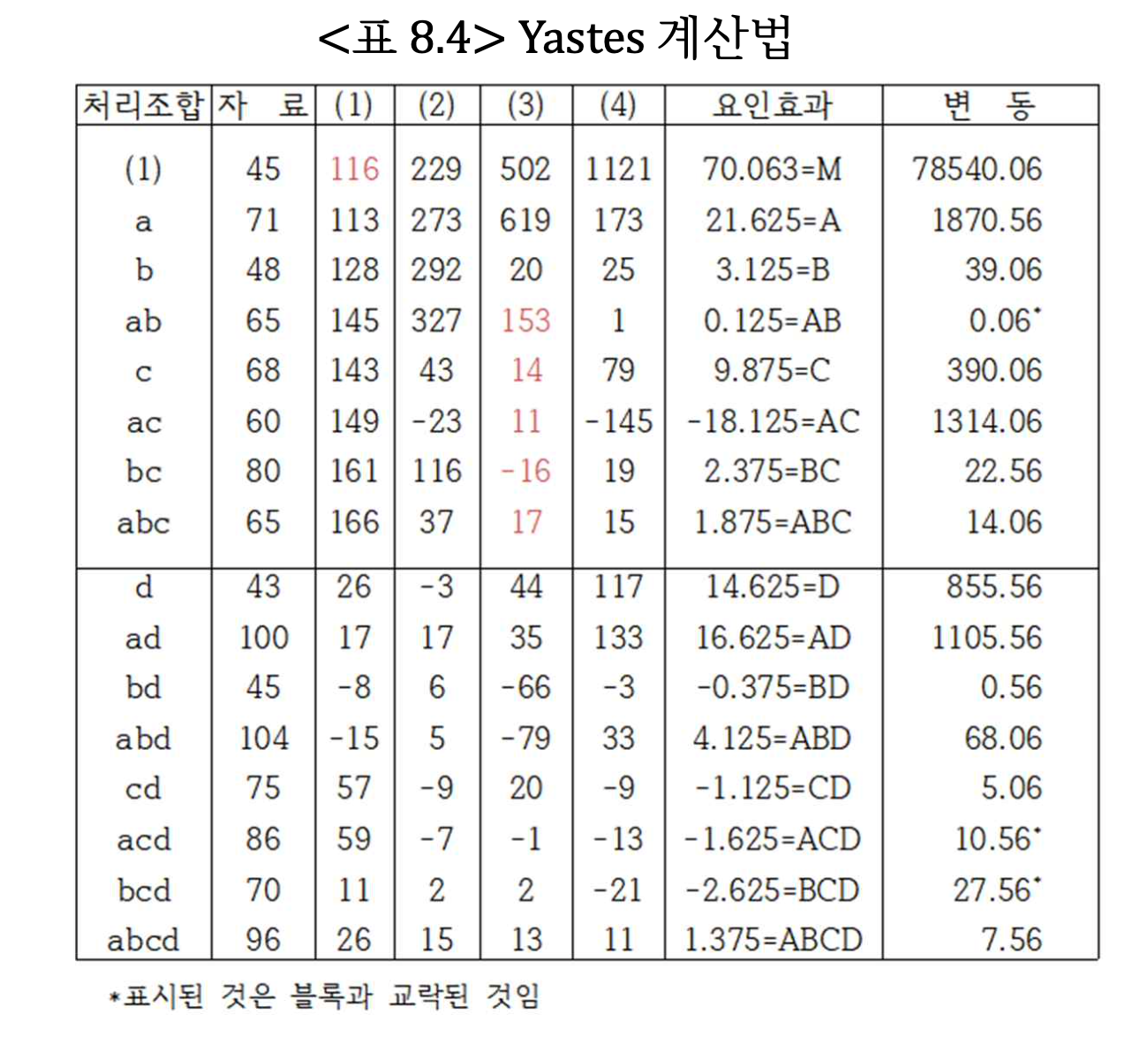
이제 위의 결과를 이용하여 교과서 표 8.4 와 동일한 Yates 계산의 결과를 구해보자.
treat effect
A A 21.625
B B 3.125
AB AB 0.125
C C 9.875
AC AC -18.125
BC BC 2.375
ABC ABC 1.875
D D 14.625
AD AD 16.625
BD BD -0.375
ABD ABD 4.125
CD CD -1.125
ACD ACD -1.625
BCD BCD -2.625
ABCD ABCD 1.375
treat effect
1 (0) 70.0625
A A 21.6250
B B 3.1250
AB AB 0.1250
C C 9.8750
AC AC -18.1250
BC BC 2.3750
ABC ABC 1.8750
D D 14.6250
AD AD 16.6250
BD BD -0.3750
ABD ABD 4.1250
CD CD -1.1250
ACD ACD -1.6250
BCD BCD -2.6250
ABCD ABCD 1.3750
위에서 구한 데이터프레임의 effect 는 평균 효과를 의미한다. 예를 들어서 처리 \(A\) 에 대한 효과는 다음과 같이 구한다.
\[
\begin{aligned}
A & = \frac{1}{8} (a + ab + ac + abc + ad + abd + acd + abcd - (0) - b -c -bc -d - bd - cd -bcd) \\
& =\frac{1}{8} (T_{1...} - T_{0...}) \\
& = \bar {y}_{1...} - \bar {y}_{0...} \\
& = 21.625
\end{aligned}
\]
따라서 제곱합을 구하는 방법은 처리합의 차를 제곱한 값 \((T_{1...} - T_{0...})^2\) 을 총 실험의 크기 \(n=16\) 으로 나눈다. 이는 평균처리 효과를 제곱한 값에 4를 곱해주는 양과 같다.
treat effect SS
1 (0) 70.0625 78540.0625
A A 21.6250 1870.5625
B B 3.1250 39.0625
AB AB 0.1250 0.0625
C C 9.8750 390.0625
AC AC -18.1250 1314.0625
BC BC 2.3750 22.5625
ABC ABC 1.8750 14.0625
D D 14.6250 855.5625
AD AD 16.6250 1105.5625
BD BD -0.3750 0.5625
ABD ABD 4.1250 68.0625
CD CD -1.1250 5.0625
ACD ACD -1.6250 10.5625
BCD BCD -2.6250 27.5625
ABCD ABCD 1.3750 7.5625
예제 8.2 Yates 계산
6.1.5 블럭변동
자료에서 블럭의 변동을 구하는 방법은 교과서 231 에 나온 것처럼 각 블럭에 대한 관측값의 합을 구해서 변동의 공식을 이용할 수 있다. 각 블럭 안의 관측값들 합을 \(T_i\)라고 하면
treat effect SS
AB AB 0.125 0.0625
ACD ACD -1.625 10.5625
BCD BCD -2.625 27.5625
6.1.6 핵심요인의 선별
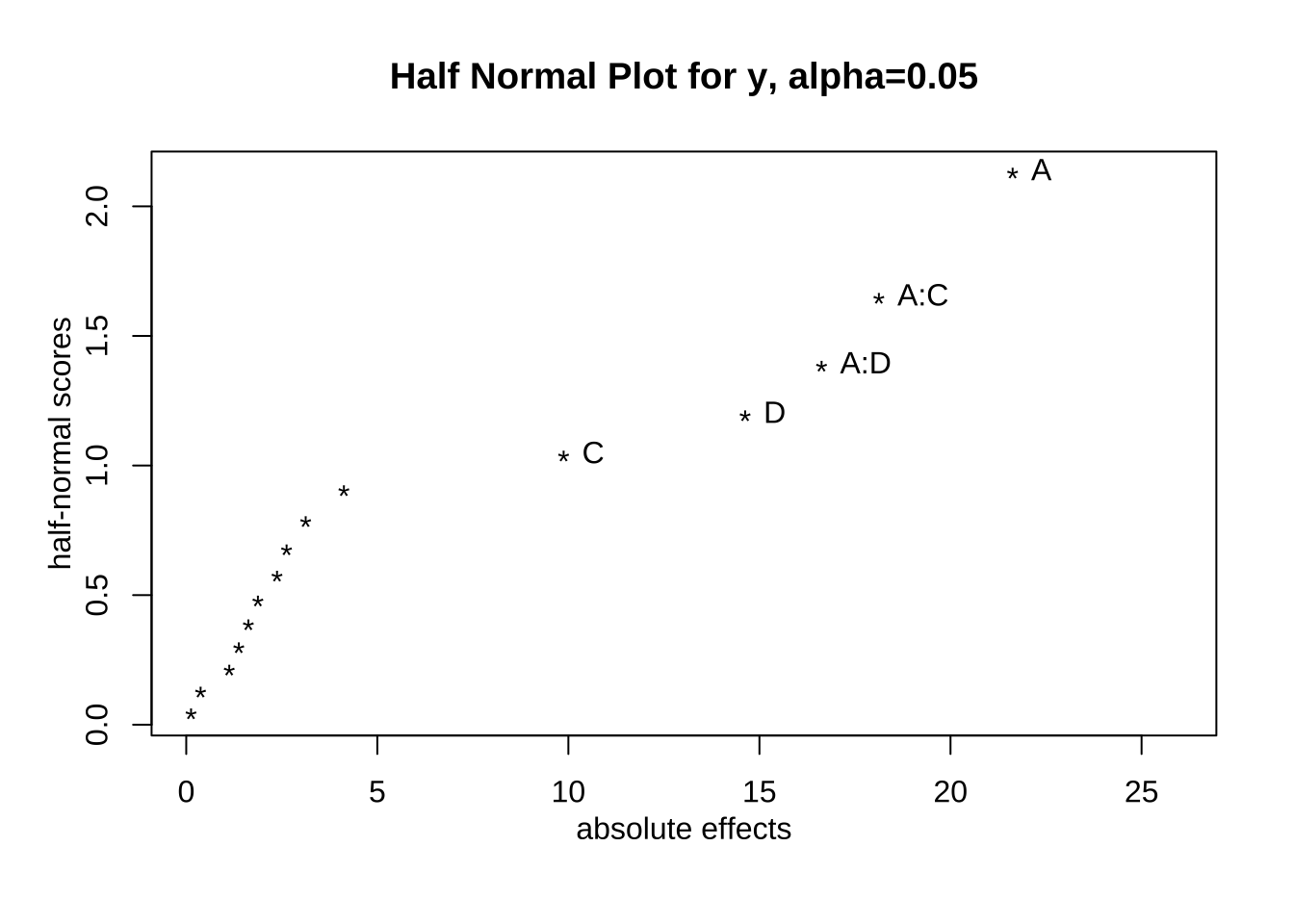
핵심요인의 선별하기 위하여 먼저 각 처리의 제곱합을 순서대로 나열해 보자. 주요인 \(A\), \(C\), \(D\) 와 상호작용 효과 \(AC\) 와 \(AD\)의 제곱합이 다른 것보다 크게 나타나는 것을 볼 수 있다.
yates_effect %>%arrange(desc(SS))
treat effect SS
1 (0) 70.0625 78540.0625
A A 21.6250 1870.5625
AC AC -18.1250 1314.0625
AD AD 16.6250 1105.5625
D D 14.6250 855.5625
C C 9.8750 390.0625
ABD ABD 4.1250 68.0625
B B 3.1250 39.0625
BCD BCD -2.6250 27.5625
BC BC 2.3750 22.5625
ABC ABC 1.8750 14.0625
ACD ACD -1.6250 10.5625
ABCD ABCD 1.3750 7.5625
CD CD -1.1250 5.0625
BD BD -0.3750 0.5625
AB AB 0.1250 0.0625
이제 모든 효과가 포함된 완전모형(full model)을 적합시키고 반정규확률 그림을 그려서 핵심효인을 다시 찾아보자. 제곱합을 비교할 때와 같이 주요인 \(A\), \(C\), \(D\) 와 상호작용 효과 \(AC\) 와 \(AD\)이 핵심 요인으로 보여진다.
위의 핵심요인의 선별 결과를 고려하여 주요인 \(A\), \(B\), \(C\), \(D\) 와 상호작용 효과 \(AC\) 와 \(AD\) 를 포함하는 축소된 모형을 최종모형으로 적합해 보자. 축소모형에는 당연히 블럭효과도 포함해야 한다. 또한 오차항에는 블럭과 교럭돤 상호작용 효과들과 축소모형에 포함된 효과들을 제외한 다른 효과들이 풀링된다.
\[ SS_E = SS_{B \times C} + SS_{B \times D} + SS_{C \times D} + SS_{A \times B \times C} + SS_{A \times B \times D } + SS_{A \times B \times C \times D}\]
finalmodel <-lm(y ~ block + A +B + C+ D + A:C + A:D, data=df)anova(finalmodel)
Analysis of Variance Table
Response: y
Df Sum Sq Mean Sq F value Pr(>F)
block 3 38.19 12.73 0.6479 0.6123498
A 1 1870.56 1870.56 95.2142 6.66e-05 ***
B 1 39.06 39.06 1.9883 0.2081893
C 1 390.06 390.06 19.8547 0.0043020 **
D 1 855.56 855.56 43.5493 0.0005821 ***
A:C 1 1314.06 1314.06 66.8876 0.0001800 ***
A:D 1 1105.56 1105.56 56.2747 0.0002902 ***
Residuals 6 117.88 19.65
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
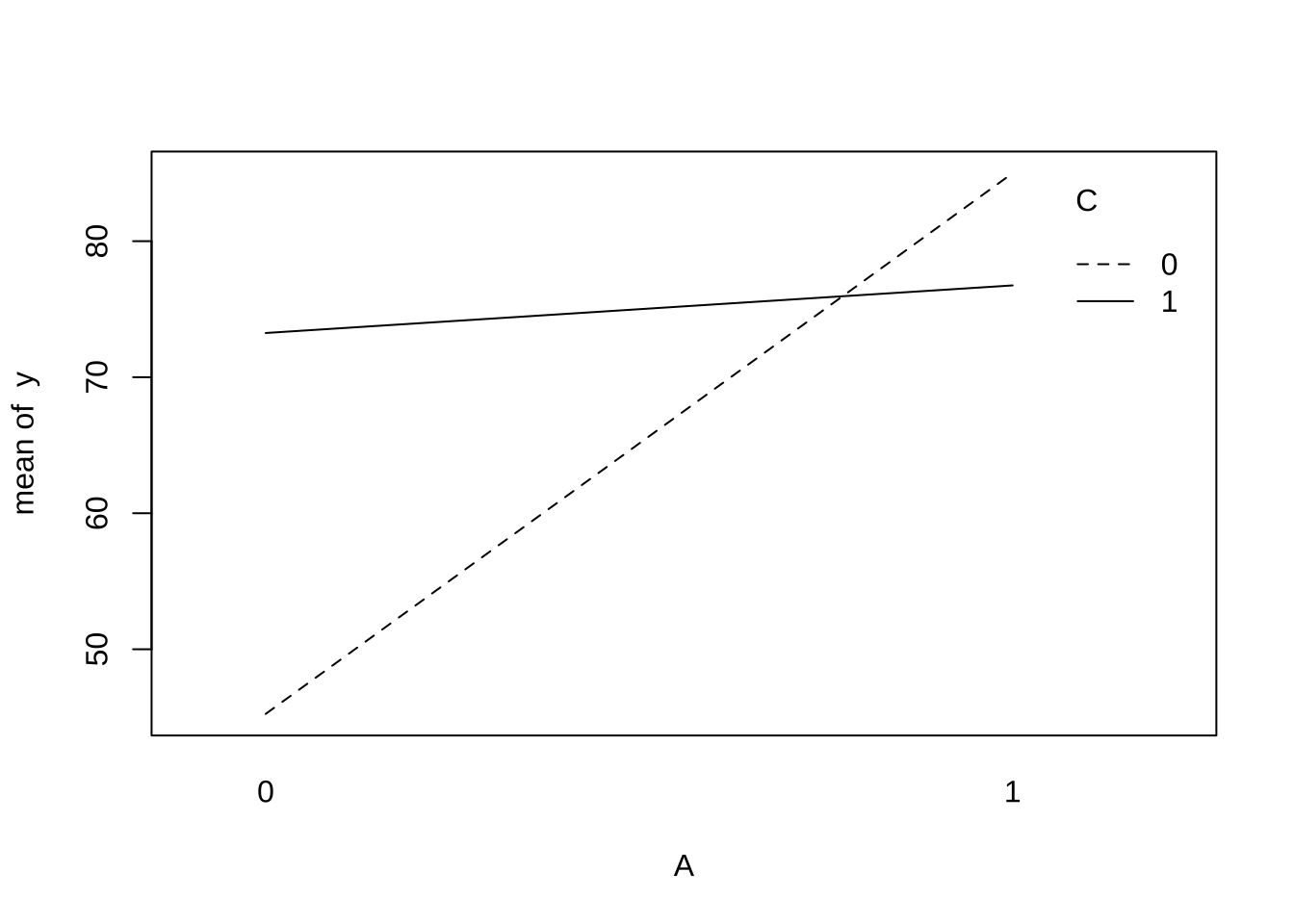
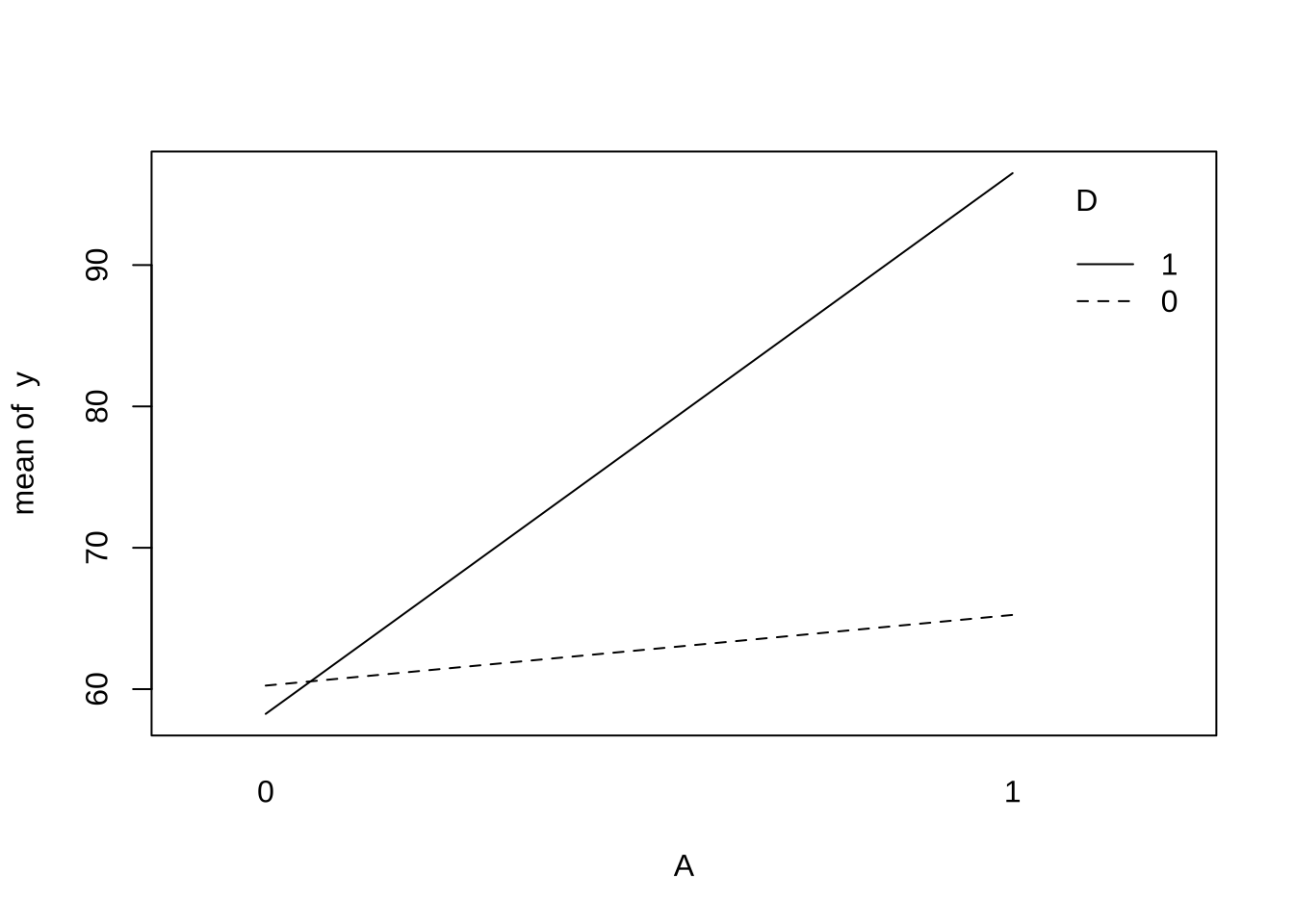
6.2 상호작용 그림
with(df, interaction.plot(x.factor = A, trace.factor = C, response = y))
with(df, interaction.plot(x.factor = A, trace.factor = D, response = y))