대부분의 연구나 실험의 목적은 집단(group, 그룹)간의 유의한 차이가 있는지 검증하는 것이다. 집단의 차이는 집단의 특성를 파악할 수 있는 기술 통계량(descriptive statistics)를 사용하여 비교 할 수 있다. 즉 각 집단에 대한 관심변수의 평균, 중앙값 등으로 집단 간 중심의 차이를 비교할 수 있고 표준편차, 사분위범위(Inter Quartile Range; IQR) 등을 사용하면 퍼진 정도도 비교할 수 있다.
이러한 기술 통계량을 이용한 비교도 의미가 있지만 그림을 통하여 집단 간의 차이를 나타내는 것이 자료의 특성을 이해하는데 더 큰 도움이 된다. 그림을 이용하면 자료의 전체적인 퍼진 정도를 파악하기 쉽고 이상치(outlier) 등을 알아내는데 도움이 된다.
이 장에서는 교과서에 제시된 예제 자료를 R 프로그램을 이용하여 분석할 것이다. 기술 통계량과 그림을 이용하여 집단을 비교하는 방법을 알아보고자 한다.
A.1 두 개 모집단의 비교
A.1.1 예제 2.2 자료
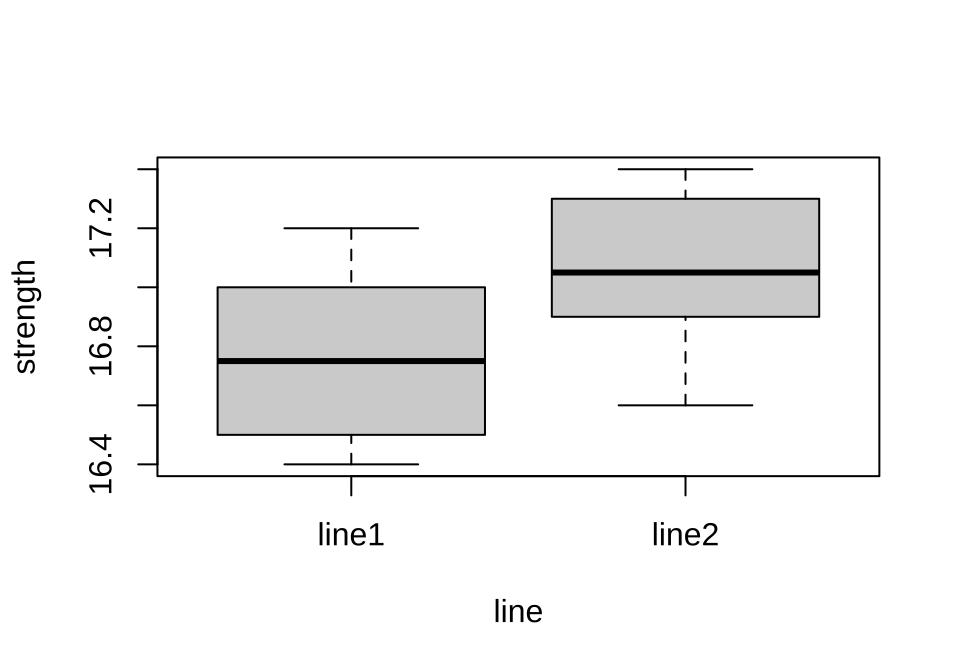
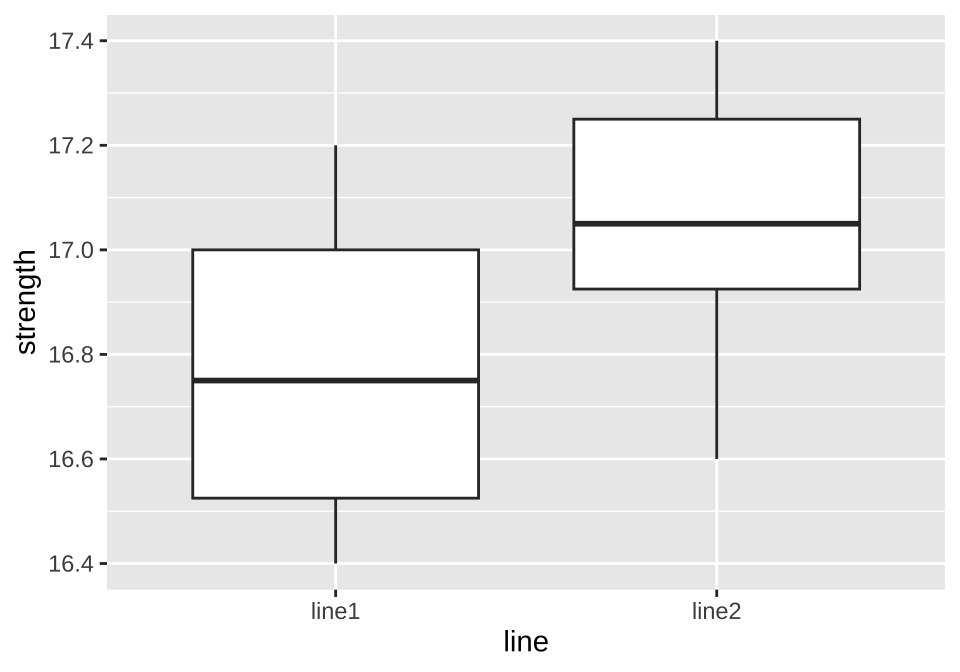
교재 2장의 예제 2.2 에서 소개된 인장 강도의 자료는 시멘트 공장의 2개의 생산라인에서 생산된 시멘트의 인장 강도를 측정한 것이다. 분석의 목적은 2개의 생산라인의 분포가 동일한지를 비교하는 것이다.
먼저 R로 데이터프레임(data.frame)으로 만들어 보자. 예제 자료를 line1 과 line2 의 벡터 형식으로 만들고 data.frame의 형식인 df0에 저장하려면 다음과 같은 명령어를 사용하면 된다.
data.frame 인 df0에는 각 그룹(line1과 line2)에 대한 10개의 자료가 2개의 열(column)에 각각 저장되어 있다. 이러한 자료의 형태를 넓은 형태의 자료(wide-format data)라고 부른다.
위에서 만든 데이터프레임 df0 를 변형하여 반응값들을 하나의 변수(strength)로 합치고, 집단을 나타내는 변수 line를 생성하여 다른 형태의 데이터프레임 df를 다음과 같이 만들어 보자. 아래와 같은 형태의 자료를 좁은 형태의 자료(narrow-format data)라고 부른다. 넓은 형태보다 좁은 형태의 자료가 통계적 분석을 적용하기 편하다.
# convert wide format to long formatdf22<- df220 %>%pivot_longer(cols =everything(), names_to ="line", values_to ="strength") %>% dplyr::arrange(line)df22
넓은 형태의 자료 df0에 대한 요약통계(평균, 중앙값, 사분위수, 최소, 최대 등)를 다음과 같이 summary 함수를 이용하여 구하고 집단간의 차이를 비교할 수 있다.
summary(df220)
line1 line2
Min. :16.40 Min. :16.60
1st Qu.:16.52 1st Qu.:16.93
Median :16.75 Median :17.05
Mean :16.78 Mean :17.05
3rd Qu.:17.00 3rd Qu.:17.25
Max. :17.20 Max. :17.40
A.1.3 기술 통계량에 의한 요약 - 좁은 형태의 자료
좁은 형태의 자료 df에 대해서는 다음과 같이 먼저 group_by함수로 집단을 구별하는 변수를 지정한다. 그 다음으로 summarise함수를 이용하여 여러 가지 통계량를 집단별로 계산할 수 있다.